





19,612
社区成员
 发帖
发帖 与我相关
与我相关 我的任务
我的任务
 分享
分享防火墙,其实说白了讲,就是用于实现Linux下访问控制的功能的,它分为硬件的或者软件的防火墙两种。无论是在哪个网络中,防火墙工作的地方一定是在网络的边缘。而我们的任务就是需要去定义到底防火墙如何工作,这就是防火墙的策略,规则,以达到让它对出入网络的IP、数据进行检测。
目前市面上比较常见的有3、4层的防火墙,叫网络层的防火墙,还有7层的防火墙,其实是代理层的网关。
对于TCP/IP的七层模型来讲,我们知道第三层是网络层,三层的防火墙会在这层对源地址和目标地址进行检测。但是对于七层的防火墙,不管你源端口或者目标端口,源地址或者目标地址是什么,都将对你所有的东西进行检查。所以,对于设计原理来讲,七层防火墙更加安全,但是这却带来了效率更低。所以市面上通常的防火墙方案,都是两者结合的。而又由于我们都需要从防火墙所控制的这个口来访问,所以防火墙的工作效率就成了用户能够访问数据多少的一个最重要的控制,配置的不好甚至有可能成为流量的瓶颈。
二:iptables 的历史以及工作原理
1.iptables的发展:
iptables的前身叫ipfirewall (内核1.x时代),这是一个作者从freeBSD上移植过来的,能够工作在内核当中的,对数据包进行检测的一款简易访问控制工具。但是ipfirewall工作功能极其有限(它需要将所有的规则都放进内核当中,这样规则才能够运行起来,而放进内核,这个做法一般是极其困难的)。当内核发展到2.x系列的时候,软件更名为ipchains,它可以定义多条规则,将他们串起来,共同发挥作用,而现在,它叫做iptables,可以将规则组成一个列表,实现绝对详细的访问控制功能。
他们都是工作在用户空间中,定义规则的工具,本身并不算是防火墙。它们定义的规则,可以让在内核空间当中的netfilter来读取,并且实现让防火墙工作。而放入内核的地方必须要是特定的位置,必须是tcp/ip的协议栈经过的地方。而这个tcp/ip协议栈必须经过的地方,可以实现读取规则的地方就叫做 netfilter.(网络过滤器)
作者一共在内核空间中选择了5个位置,
1.内核空间中:从一个网络接口进来,到另一个网络接口去的
2.数据包从内核流入用户空间的
3.数据包从用户空间流出的
4.进入/离开本机的外网接口
5.进入/离开本机的内网接口
2.iptables的工作机制
从上面的发展我们知道了作者选择了5个位置,来作为控制的地方,但是你有没有发现,其实前三个位置已经基本上能将路径彻底封锁了,但是为什么已经在进出的口设置了关卡之后还要在内部卡呢? 由于数据包尚未进行路由决策,还不知道数据要走向哪里,所以在进出口是没办法实现数据过滤的。所以要在内核空间里设置转发的关卡,进入用户空间的关卡,从用户空间出去的关卡。那么,既然他们没什么用,那我们为什么还要放置他们呢?因为我们在做NAT和DNAT的时候,目标地址转换必须在路由之前转换。所以我们必须在外网而后内网的接口处进行设置关卡。
这五个位置也被称为五个钩子函数(hook functions),也叫五个规则链。
1.PREROUTING (路由前)
2.INPUT (数据包流入口)
3.FORWARD (转发管卡)
4.OUTPUT(数据包出口)
5.POSTROUTING(路由后)
这是NetFilter规定的五个规则链,任何一个数据包,只要经过本机,必将经过这五个链中的其中一个链。
3.防火墙的策略
防火墙策略一般分为两种,一种叫“通”策略,一种叫“堵”策略,通策略,默认门是关着的,必须要定义谁能进。堵策略则是,大门是洞开的,但是你必须有身份认证,否则不能进。所以我们要定义,让进来的进来,让出去的出去,所以通,是要全通,而堵,则是要选择。当我们定义的策略的时候,要分别定义多条功能,其中:定义数据包中允许或者不允许的策略,filter过滤的功能,而定义地址转换的功能的则是nat选项。为了让这些功能交替工作,我们制定出了“表”这个定义,来定义、区分各种不同的工作功能和处理方式。
我们现在用的比较多个功能有3个:
1.filter 定义允许或者不允许的
2.nat 定义地址转换的
3.mangle功能:修改报文原数据
我们修改报文原数据就是来修改TTL的。能够实现将数据包的元数据拆开,在里面做标记/修改内容的。而防火墙标记,其实就是靠mangle来实现的。
小扩展:
对于filter来讲一般只能做在3个链上:INPUT ,FORWARD ,OUTPUT
对于nat来讲一般也只能做在3个链上:PREROUTING ,OUTPUT ,POSTROUTING
而mangle则是5个链都可以做:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING
iptables/netfilter(这款软件)是工作在用户空间的,它可以让规则进行生效的,本身不是一种服务,而且规则是立即生效的。而我们iptables现在被做成了一个服务,可以进行启动,停止的。启动,则将规则直接生效,停止,则将规则撤销。
iptables还支持自己定义链。但是自己定义的链,必须是跟某种特定的链关联起来的。在一个关卡设定,指定当有数据的时候专门去找某个特定的链来处理,当那个链处理完之后,再返回。接着在特定的链中继续检查。
注意:规则的次序非常关键,谁的规则越严格,应该放的越靠前,而检查规则的时候,是按照从上往下的方式进行检查的。
三.规则的写法:
iptables定义规则的方式比较复杂:
格式:iptables [-t table] COMMAND chain CRETIRIA -j ACTION
-t table :3个filter nat mangle
COMMAND:定义如何对规则进行管理
chain:指定你接下来的规则到底是在哪个链上操作的,当定义策略的时候,是可以省略的
CRETIRIA:指定匹配标准
-j ACTION :指定如何进行处理
比如:不允许172.16.0.0/24的进行访问。
iptables -t filter -A INPUT -s 172.16.0.0/16 -p udp --dport 53 -j DROP
当然你如果想拒绝的更彻底:
iptables -t filter -R INPUT 1 -s 172.16.0.0/16 -p udp --dport 53 -j REJECT
iptables -L -n -v 可以写成 iptables -nvL #查看定义规则的详细信息,如只显示INPUT链: iptables -nvL INPUT
L后不带具体链名,表示列出所有的链。不带-t选项默认filter.
四:详解COMMAND:
1.链管理命令(这都是立即生效的)
-P :设置默认策略的(设定默认门是关着的还是开着的)
默认策略一般只有两种
iptables -P INPUT (DROP|ACCEPT) 默认是关的/默认是开的
比如:
iptables -P INPUT DROP 这就把默认规则给拒绝了。并且没有定义哪个动作,所以关于外界连接的所有规则包括Xshell连接之类的,远程连接都被拒绝了。
-F: FLASH,清空规则链的(注意每个链的管理权限)
iptables -t nat -F PREROUTING
iptables -t nat -F 清空nat表的所有链
-N:NEW 支持用户新建一个链
iptables -N inbound_tcp_web 表示附在tcp表上用于检查web的。
-X: 用于删除用户自定义的空链
使用方法跟-N相同,但是在删除之前必须要将里面的链给清空昂了
-E:用来Rename chain主要是用来给用户自定义的链重命名
-E oldname newname
-Z:清空链,及链中默认规则的计数器的(有两个计数器,被匹配到多少个数据包,多少个字节)
iptables -Z :清空
2.规则管理命令
-A:追加,在当前链的最后新增一个规则
-I num : 插入,把当前规则插入为第几条。
-I 3 :插入为第三条
-R num:Replays替换/修改第几条规则
格式:iptables -R 3 …………
-D num:删除,明确指定删除第几条规则
3.查看管理命令 “-L”
附加子命令
-n:以数字的方式显示ip,它会将ip直接显示出来,如果不加-n,则会将ip反向解析成主机名。
-v:显示详细信息
-vv
-vvv :越多越详细
-x:在计数器上显示精确值,不做单位换算
--line-numbers : 显示规则的行号,可简写成 --line
-t nat:显示所有的关卡的信息
五:详解匹配标准
1.通用匹配:源地址目标地址的匹配
-s:指定作为源地址匹配,这里不能指定主机名称,必须是IP
IP | IP/MASK | 0.0.0.0/0.0.0.0
而且地址可以取反,加一个“!”表示除了哪个IP之外
-d:表示匹配目标地址
-p:用于匹配协议的(这里的协议通常有3种,TCP/UDP/ICMP)
-i eth0:从这块网卡流入的数据
流入一般用在INPUT和PREROUTING上
-o eth0:从这块网卡流出的数据
流出一般在OUTPUT和POSTROUTING上
2.扩展匹配
2.1隐含扩展:对协议的扩展
-p tcp :TCP协议的扩展。一般有三种扩展
--dport XX-XX:指定目标端口,不能指定多个非连续端口,只能指定单个端口,比如
--dport 21 或者 --dport 21-23 (此时表示21,22,23)
--sport:指定源端口
--tcp-fiags:TCP的标志位(SYN,ACK,FIN,PSH,RST,URG)
对于它,一般要跟两个参数:
1.检查的标志位
2.必须为1的标志位
--tcpflags syn,ack,fin,rst syn = --syn
表示检查这4个位,这4个位中syn必须为1,其他的必须为0。所以这个意思就是用于检测三次握手的第一次包的。对于这种专门匹配第一包的SYN为1的包,还有一种简写方式,叫做--syn
-p udp:UDP协议的扩展
--dport
--sport
-p icmp:icmp数据报文的扩展
--icmp-type:
echo-request(请求回显),一般用8 来表示
所以 --icmp-type 8 匹配请求回显数据包
echo-reply (响应的数据包)一般用0来表示
2.2显式扩展(-m)
扩展各种模块
-m multiport:表示启用多端口扩展
之后我们就可以启用比如 --dports 21,23,80
六:详解-j ACTION
常用的ACTION:
DROP:悄悄丢弃
一般我们多用DROP来隐藏我们的身份,以及隐藏我们的链表
REJECT:明示拒绝
ACCEPT:接受
custom_chain:转向一个自定义的链
DNAT
SNAT
MASQUERADE:源地址伪装
REDIRECT:重定向:主要用于实现端口重定向
MARK:打防火墙标记的
RETURN:返回
在自定义链执行完毕后使用返回,来返回原规则链。
--------------
iptables执行规则时,是从从规则表中从上至下顺序执行的,如果没遇到匹配的规则,就一条一条往下执行,如果遇到匹配的规则后,那么就执行本规则,执行后根据本规则的动作(accept, reject, log等),决定下一步执行的情况,后续执行一般有三种情况。
1。一种是继续执行当前规则队列内的下一条规则。比如执行过Filter队列内的LOG后,还会执行Filter队列内的下一条规则。
2。一种是中止当前规则队列的执行,转到下一条规则队列。比如从执行过accept后就中断Filter队列内其它规则,跳到nat队列规则去执行
3。一种是中止所有规则队列的执行。
-j 参数用来指定要进行的处理动作,常用的处理动作包括:ACCEPT、REJECT、DROP、REDIRECT、MASQUERADE、LOG、DNAT、SNAT、MIRROR、QUEUE、RETURN、MARK,分别说明如下:
ACCEPT 将封包放行,进行完此处理动作后,将不再比对其它规则,直接跳往下一个规则链(natostrouting)。
REJECT 拦阻该封包,并传送封包通知对方,可以传送的封包有几个选择:ICMP port-unreachable、ICMP echo-reply 或是 tcp-reset(这个封包会要求对方关闭联机),进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
例如:iptables -A FORWARD -p TCP --dport 22 -j REJECT --reject-with tcp-reset
DROP 丢弃封包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
REDIRECT 将封包重新导向到另一个端口(PNAT),进行完此处理动作后,将会继续比对其它规则。
这个功能可以用来实作通透式porxy 或用来保护 web 服务器。
例如:iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
MASQUERADE 改写封包来源 IP 为防火墙 NIC IP,可以指定 port 对应的范围,进行完此处理动作后,直接跳往下一个规则(mangleostrouting)。这个功能与 SNAT 略有不同,当进行 IP 伪装时,不需指定要伪装成哪个 IP,IP 会从网卡直接读,当使用拨接连线时,IP 通常是由 ISP 公司的 DHCP 服务器指派的,这个时候 MASQUERADE 特别有用。
例如:iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1024-31000
LOG 将封包相关讯息纪录在 /var/log 中,详细位置请查阅 /etc/syslog.conf 组态档,进行完此处理动作后,将会继续比对其规则。
例如:iptables -A INPUT -p tcp -j LOG --log-prefix "INPUT packets"
SNAT 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则(mangleostrouting)。
例如:iptables -t nat -A POSTROUTING -p tcp-o eth0 -j SNAT --to-source 194.236.50.155-194.236.50.160:1024-32000
DNAT 改写封包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规炼(filter:input 或 filter:forward)。
例如:iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.1-192.168.1.10:80-100
MIRROR 镜射封包,也就是将来源 IP 与目的地 IP 对调后,将封包送回,进行完此处理动作后,将会中断过滤程序。
QUEUE 中断过滤程序,将封包放入队列,交给其它程序处理。透过自行开发的处理程序,可以进行其它应用,
例如:计算联机费......等。
RETURN 结束在目前规则炼中的过滤程序,返回主规则炼继续过滤,如果把自订规则炼看成是一个子程序,那么这个动作,就相当提早结束子程序并返回到主程序中。
MARK 将封包标上某个代号,以便提供作为后续过滤的条件判断依据,进行完此处理动作后,将会继续比对其它规则。
例如:iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 2
------------ref:http://bbs.chinaunix.net/thread-936284-1-1.html
练习题1:
只要是来自于172.16.0.0/16网段的都允许访问我本机的172.16.100.1的SSHD服务
分析:首先肯定是在允许表中定义的。因为不需要做NAT地址转换之类的,然后查看我们SSHD服务,在22号端口上,处理机制是接受,对于这个表,需要有一来一回两个规则,如果我们允许也好,拒绝也好,对于访问本机服务,我们最好是定义在INPUT链上,而OUTPUT再予以定义就好。(会话的初始端先定义),所以加规则就是:
定义进来的: iptables -t filter -A INPUT -s 172.16.0.0/16 -d 172.16.100.1 -p tcp --dport 22 -j ACCEPT
定义出去的: iptables -t filter -A OUTPUT -s 172.16.100.1 -d 172.16.0.0/16 -p tcp --dport 22 -j ACCEPT
将默认策略改成DROP:
iptables -P INPUT DROP
iptables -P OUTPUT DROP
iptables -P FORWARD DROP
七:状态检测:
是一种显式扩展,用于检测会话之间的连接关系的,有了检测我们可以实现会话间功能的扩展
什么是状态检测?对于整个TCP协议来讲,它是一个有连接的协议,三次握手中,第一次握手,我们就叫NEW连接,而从第二次握手以后的,ack都为1,这是正常的数据传输,和tcp的第二次第三次握手,叫做已建立的连接(ESTABLISHED),还有一种状态,比较诡异的,比如:SYN=1 ACK=1 RST=1,对于这种我们无法识别的,我们都称之为INVALID无法识别的。还有第四种,FTP这种古老的拥有的特征,每个端口都是独立的,21号和20号端口都是一去一回,他们之间是有关系的,这种关系我们称之为RELATED。
所以我们的状态一共有四种:
NEW
ESTABLISHED
RELATED
INVALID
所以我们对于刚才的练习题,可以增加状态检测。比如进来的只允许状态为NEW和ESTABLISHED的进来,出去只允许ESTABLISHED的状态出去,这就可以将比较常见的反弹式木马有很好的控制机制。
对于练习题的扩展:
进来的拒绝出去的允许,进来的只允许ESTABLISHED进来,出去只允许ESTABLISHED出去。默认规则都使用拒绝
iptables -nvL --line-numbers :查看之前的规则位于第几行
改写INPUT
iptables -R INPUT 2 -s 172.16.0.0/16 -d 172.16.100.1 -p tcp --dport 22 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -R OUTPUT 1 -m state --state ESTABLISHED -j ACCEPT (-m conntrack --ctstate与-m state --state可互换)
此时如果想再放行一个80端口如何放行呢?
iptables -A INPUT -d 172.16.100.1 -p tcp --dport 80 -m state --state NEW,ESTABLISHED -j ACCEPT
iptables -R INPUT 1 -d 172.16.100.1 -p udp --dport 53 -j ACCEPT
练习题2:
假如我们允许自己ping别人(自己主机output的icmp类型8 accept output,别人响应的icmp类型0 accept input),但是别人ping自己ping不通(别人发起的icmp类型8 drop input,自己响应的icmp类型0 drop output--其实icmp 8输入都被drop了,icmp 0更没输出了)如何实现呢?
分析:对于ping这个协议,icmp请求(主动发起的)包类型应该为8,icmp应答包类型应该为0.我们为了达到目的,需要8出去,允许0进来
iptables -P INPUT DROP
在出去的端口上:iptables -A OUTPUT -p icmp --icmp-type 8 -j ACCEPT //8:echo-request icmp请求
在进来的端口上:iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT //0:echo-reply icmp应答
小扩展:对于127.0.0.1比较特殊,我们需要明确定义它
iptables -A INPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT
iptables -A OUTPUT -s 127.0.0.1 -d 127.0.0.1 -j ACCEPT
八:SNAT和DNAT的实现
由于我们现在IP地址十分紧俏,已经分配完了,这就导致我们必须要进行地址转换,来节约我们仅剩的一点IP资源。那么通过iptables如何实现NAT的地址转换呢?
1.SNAT基于原地址的转换
基于原地址的转换一般用在我们的许多内网用户通过一个外网的口上网的时候,这时我们将我们内网的地址转换为一个外网的IP,我们就可以实现连接其他外网IP的功能。
所以我们在iptables中就要定义到底如何转换:
定义的样式:
比如我们现在要将所有192.168.10.0网段的IP在经过的时候全都转换成172.16.100.1这个假设出来的外网地址:
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j SNAT --to-source 172.16.100.1
这样,只要是来自本地网络的试图通过网卡访问网络的,都会被统统转换成172.16.100.1这个IP.
那么,如果172.16.100.1不是固定的怎么办?
我们都知道当我们使用联通或者电信上网的时候,一般它都会在每次你开机的时候随机生成一个外网的IP,意思就是外网地址是动态变换的。这时我们就要将外网地址换成 MASQUERADE(动态伪装):它可以实现自动寻找到外网地址,而自动将其改为正确的外网地址。所以,我们就需要这样设置:
iptables -t nat -A POSTROUTING -s 192.168.10.0/24 -j MASQUERADE
这里要注意:地址伪装并不适用于所有的地方。
2.DNAT目标地址转换
对于目标地址转换,数据流向是从外向内的,外面的是客户端,里面的是服务器端 通过目标地址转换,我们可以让外面的ip通过我们对外的外网ip来访问我们服务器不同的服务器,而我们的服务却放在内网服务器的不同的服务器上 。
如何做目标地址转换呢?:
iptables -t nat -A PREROUTING -d 192.168.10.18 -p tcp --dport 80 -j DNAT --todestination 172.16.100.2
目标地址转换要做在到达网卡之前进行转换,所以要做在PREROUTING这个位置上
九:控制规则的存放以及开启
注意:你所定义的所有内容,当你重启的时候都会失效,要想我们能够生效,需要使用一个命令将它保存起来
1.service iptables save 命令
它会保存在/etc/sysconfig/iptables这个文件中
2.iptables-save 命令
iptables-save > /etc/sysconfig/iptables
3.iptables-restore 命令
开机的时候,它会自动加载/etc/sysconfig/iptabels
如果开机不能加载或者没有加载,而你想让一个自己写的配置文件(假设为iptables.2)手动生效的话:
iptables-restore < /etc/sysconfig/iptables.2
则完成了将iptables中定义的规则手动生效
十:总结
Iptables是一个非常重要的工具,它是每一个防火墙上几乎必备的设置,也是我们在做大型网络的时候,为了很多原因而必须要设置的。学好Iptables,可以让我们对整个网络的结构有一个比较深刻的了解,同时,我们还能够将内核空间中数据的走向以及linux的安全给掌握的非常透彻。我们在学习的时候,尽量能结合着各种各样的项目,实验来完成,这样对你加深iptables的配置,以及各种技巧有非常大的帮助。
ref:https://blog.csdn.net/qq_38892883/article/details/79709023
附加iptables比较好的文章:
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------ref:https://developer.aliyun.com/article/354549
iptables是组成Linux平台下的包过滤防火墙,与大多数的Linux软件一样,这个包过滤防火墙是免费的,它可以代替昂贵的商业防火墙解决方案,完成封包过滤、封包重定向和网络地址转换(NAT)等功能。在日常Linux运维工作中,经常会设置iptables防火墙规则,用来加固服务安全。以下对iptables的规则使用做了总结性梳理:
iptables首先需要了解的:
1)规则概念
规则(rules)其实就是网络管理员预定义的条件,规则一般的定义为“如果数据包头符合这样的条件,就这样处理这个数据包”。规则存储在内核空间的信息 包过滤表中,这些规则分别指定了源地址、目的地址、传输协议(如TCP、UDP、ICMP)和服务类型(如HTTP、FTP和SMTP)等。
当数据包与规则匹配时,iptables就根据规则所定义的方法来处理这些数据包,如放行(accept),拒绝(reject)和丢弃(drop)等。配置防火墙的主要工作是添加,修改和删除等规则。
其中:
匹配(match):符合指定的条件,比如指定的 IP 地址和端口。
丢弃(drop):当一个包到达时,简单地丢弃,不做其它任何处理。
接受(accept):和丢弃相反,接受这个包,让这个包通过。
拒绝(reject):和丢弃相似,但它还会向发送这个包的源主机发送错误消息。这个错误消息可以指定,也可以自动产生。
目标(target):指定的动作,说明如何处理一个包,比如:丢弃,接受,或拒绝。
跳转(jump):和目标类似,不过它指定的不是一个具体的动作,而是另一个链,表示要跳转到那个链上。
规则(rule):一个或多个匹配及其对应的目标。
2)iptables和netfilter的关系:
Iptables和netfilter的关系是一个很容易让人搞不清的问题。很多的知道iptables却不知道 netfilter。其实iptables只是Linux防火墙的管理工具而已,位于/sbin/iptables。真正实现防火墙功能的是 netfilter,它是Linux内核中实现包过滤的内部结构。
3)iptables的规则表和链
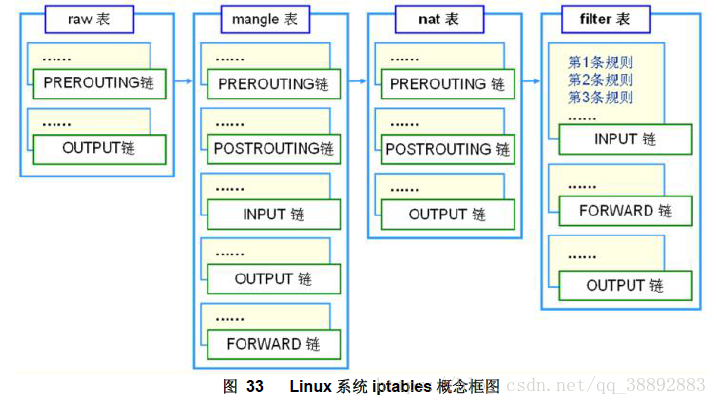
表(tables):提供特定的功能,iptables内置了4个表,即filter表、nat表、mangle表和raw表,分别用于实现包过滤,网络地址转换、包重构(修改)和数据跟踪处理。
链(chains):是数据包传播的路径,每一条链其实就是众多规则中的一个检查清单,每一条链中可以有一 条或数条规则。当一个数据包到达一个链时,iptables就会从链中第一条规则开始检查,看该数据包是否满足规则所定义的条件。如果满足,系统就会根据 该条规则所定义的方法处理该数据包;否则iptables将继续检查下一条规则,如果该数据包不符合链中任一条规则,iptables就会根据该链预先定 义的默认策略来处理数据包。
Iptables采用“表”和“链”的分层结构,在Linux中现在是四张表五个链。下面罗列一下这四张表和五个链(注意一定要明白这些表和链的关系及作用)。

规则表:
1)filter表——三个链:INPUT、FORWARD、OUTPUT
作用:过滤数据包 内核模块:iptables_filter.
2)Nat表——三个链:PREROUTING、POSTROUTING、OUTPUT
作用:用于网络地址转换(IP、端口) 内核模块:iptable_nat
3)Mangle表——五个链:PREROUTING、POSTROUTING、INPUT、OUTPUT、FORWARD
作用:修改数据包的服务类型、TTL、并且可以配置路由实现QOS内核模块:iptable_mangle(别看这个表这么麻烦,咱们设置策略时几乎都不会用到它)
4)Raw表——两个链:OUTPUT、PREROUTING
作用:决定数据包是否被状态跟踪机制处理 内核模块:iptable_raw
规则链:
1)INPUT——进来的数据包应用此规则链中的策略
2)OUTPUT——外出的数据包应用此规则链中的策略
3)FORWARD——转发数据包时应用此规则链中的策略
4)PREROUTING——对数据包作路由选择前应用此链中的规则
(记住!所有的数据包进来的时侯都先由这个链处理)
5)POSTROUTING——对数据包作路由选择后应用此链中的规则
(所有的数据包出来的时侯都先由这个链处理)
管理和设置iptables规则:
4)iptables传输数据包的过程
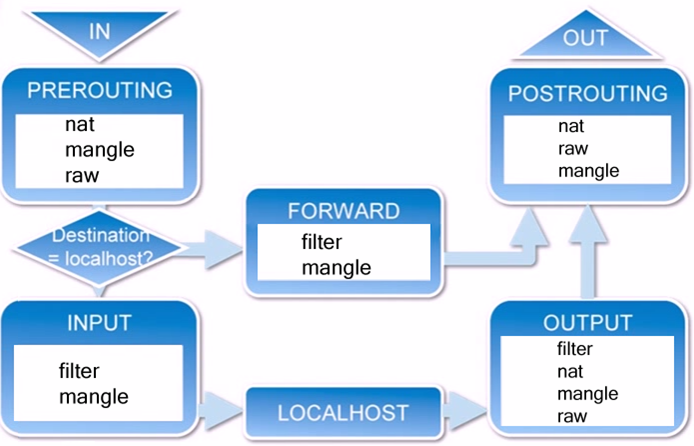

1)当一个数据包进入网卡时,它首先进入PREROUTING链,内核根据数据包目的IP判断是否需要转送出去。
2)如果数据包就是进入本机的,它就会沿着图向下移动,到达INPUT链。数据包到了INPUT链后,任何进程都会收到它。本机上运行的程序可以发送数据包,这些数据包会经过OUTPUT链,然后到达POSTROUTING链输出。
3)如果数据包是要转发出去的,且内核允许转发,数据包就会如图所示向右移动,经过FORWARD链,然后到达POSTROUTING链输出。
如果还是不清楚数据包经过iptables的基本流程,再看下面更具体的流程图:


从图中可将iptables数据包报文的处理过程分为三种类型:
1)目的为本机的报文
报文以本机为目的地址时,其经过iptables的过程为:
1.数据包从network到网卡
2.网卡接收到数据包后,进入raw表的PREROUTING链。这个链的作用是在连接跟踪之前处理报文,能够设置一条连接不被连接跟踪处理。(注:不要在raw表上添加其他规则)
3.如果设置了连接跟踪,则在这条连接上处理。
4.经过raw处理后,进入mangle表的PREROUTING链。这个链主要是用来修改报文的TOS、TTL以及给报文设置特殊的MARK。(注:通常mangle表以给报文设置MARK为主,在这个表里面,千万不要做过滤/NAT/伪装这类的事情)
5.进入nat表的PREROUTING链。这个链主要用来处理 DNAT,应该避免在这条链里面做过滤,否则可能造成有些报文会漏掉。(注:它只用来完成源/目的地址的转换)
6.进入路由决定数据包的处理。例如决定报文是上本机还是转发或者其他地方。(注:此处假设报文交给本机处理)
7.进入mangle表的 INPUT 链。在把报文实际送给本机前,路由之后,我们可以再次修改报文。
8.进入filter表的 INPUT 链。在这儿我们对所有送往本机的报文进行过滤,要注意所有收到的并且目的地址为本机的报文都会经过这个链,而不管哪个接口进来的或者它往哪儿去。
9. 进过规则过滤,报文交由本地进程或者应用程序处理,例如服务器或者客户端程序。
2)本地主机发出报文
数据包由本机发出时,其经过iptables的过程为:
1.本地进程或者应用程序(例如服务器或者客户端程序)发出数据包。
2.路由选择,用哪个源地址以及从哪个接口上出去,当然还有其他一些必要的信息。
3.进入raw表的OUTPUT链。这里是能够在连接跟踪生效前处理报文的点,在这可以标记某个连接不被连接跟踪处理。
4.连接跟踪对本地的数据包进行处理。
5.进入 mangle 表的 OUTPUT 链,在这里我们可以修改数据包,但不要做过滤(以避免副作用)。
6.进入 nat 表的 OUTPUT 链,可以对防火墙自己发出的数据做目的NAT(DNAT) 。
7.进入 filter 表的 OUTPUT 链,可以对本地出去的数据包进行过滤。
8.再次进行路由决定,因为前面的 mangle 和 nat 表可能修改了报文的路由信息。
9.进入 mangle 表的 POSTROUTING 链。这条链可能被两种报文遍历,一种是转发的报文,另外就是本机产生的报文。
10.进入 nat 表的 POSTROUTING 链。在这我们做源 NAT(SNAT),建议你不要在这做报文过滤,因为有副作用。即使你设置了默认策略,一些报文也有可能溜过去。
11.进入出去的网络接口。
3)转发报文
报文经过iptables进入转发的过程为:
1.数据包从network到网卡
2.网卡接收到数据包后,进入raw表的PREROUTING链。这个链的作用是在连接跟踪之前处理报文,能够设置一条连接不被连接跟踪处理。(注:不要在raw表上添加其他规则)
3.如果设置了连接跟踪,则在这条连接上处理。
4.经过raw处理后,进入mangle表的PREROUTING链。这个链主要是用来修改报文的TOS、TTL以及给报文设置特殊的MARK。(注:通常mangle表以给报文设置MARK为主,在这个表里面,千万不要做过滤/NAT/伪装这类的事情)
5.进入nat表的PREROUTING链。这个链主要用来处理 DNAT,应该避免在这条链里面做过滤,否则可能造成有些报文会漏掉。(注:它只用来完成源/目的地址的转换)
6.进入路由决定数据包的处理。例如决定报文是上本机还是转发或者其他地方。(注:此处假设报文进行转发)
7.进入 mangle 表的 FORWARD 链,这里也比较特殊,这是在第一次路由决定之后,在进行最后的路由决定之前,我们仍然可以对数据包进行某些修改。
8.进入 filter 表的 FORWARD 链,在这里我们可以对所有转发的数据包进行过滤。需要注意的是:经过这里的数据包是转发的,方向是双向的。
9.进入 mangle 表的 POSTROUTING 链,到这里已经做完了所有的路由决定,但数据包仍然在本地主机,我们还可以进行某些修改。
10.进入 nat 表的 POSTROUTING 链,在这里一般都是用来做 SNAT ,不要在这里进行过滤。
11.进入出去的网络接口。
接下来说下iptables规则设置用法
1)iptables的基本语法格式
iptables [-t 表名] 命令选项 [链名] [条件匹配] [-j 目标动作或跳转]
说明:
表名、链名:用于指定iptables命令所操作的表和链;
命令选项:用于指定管理iptables规则的方式(比如:插入、增加、删除、查看等;
条件匹配:用于指定对符合什么样 条件的数据包进行处理;
目标动作或跳转:用于指定数据包的处理方式(比如允许通过、拒绝、丢弃、跳转(Jump)给其它链处理。
2)iptables命令的管理控制选项
-A 在指定链的末尾添加(append)一条新的规则
-D 删除(delete)指定链中的某一条规则,可以按规则序号和内容删除
-I 在指定链中插入(insert)一条新的规则,默认在第一行添加
-R 修改、替换(replace)指定链中的某一条规则,可以按规则序号和内容替换
-L 列出(list)指定链中所有的规则进行查看(默认是filter表,如果列出nat表的规则需要添加-t,即iptables -t nat -L)
-E 重命名用户定义的链,不改变链本身
-F 清空(flush)
-N 新建(new-chain)一条用户自己定义的规则链
-X 删除指定表中用户自定义的规则链(delete-chain)
-P 设置指定链的默认策略(policy)
-Z 将所有表的所有链的字节和数据包计数器清零
-n 使用数字形式(numeric)显示输出结果
-v 查看规则表详细信息(verbose)的信息
-V 查看版本(version)
-h 获取帮助(help)
3)防火墙处理数据包的四种方式ACCEPT 允许数据包通过
DROP 直接丢弃数据包,不给任何回应信息
REJECT 拒绝数据包通过,必要时会给数据发送端一个响应的信息。
LOG在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则
4)iptables防火墙规则的保存与恢复
iptables-save把规则保存到文件中,再由目录rc.d下的脚本(/etc/rc.d/init.d/iptables)自动装载
使用命令iptables-save来保存规则。
一般用:
iptables-save > /etc/sysconfig/iptables
生成保存规则的文件/etc/sysconfig/iptables,
也可以用:
service iptables save
它能把规则自动保存在/etc/sysconfig/iptables中。
当计算机启动时,rc.d下的脚本将用命令iptables-restore调用这个文件,从而就自动恢复了规则。
5)iptables防火墙常用的策略梳理
设置默认链策略
ptables的filter表中有三种链:INPUT, FORWARD和OUTPUT。
默认的链策略是ACCEPT,可以将它们设置成DROP,如下命令就将所有包都拒绝了:
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT DROP
---------------------------------------------------------------------------------------------------------------------------
其实,在运维工作中最常用的两个规则就是白名单规则和NAT转发规则:
1)白名单规则
在linux终端命令行里操作时,如果不是默认的filter表时,需要指定表;
如果在/etc/sysconfig/iptables文件里设置,就在对应表的配置区域内设置;
上面两种方式设置效果是一样的!
比如开通本机的22端口,允许192.168.1.0网段的服务器访问(-t filter表配置可以省略,默认就是这种表的配置)
[root@linux-node1 ~]# iptables -A INPUT -s 192.168.1.0/24 -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
或者
[root@linux-node1 ~]# iptables -t filter -A INPUT -s 192.168.1.0/24 -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
开通本机的80端口,只允许192.168.1.150机器访问(32位掩码表示单机,单机指定时可以不加掩码)
[root@linux-node1 ~]# iptables -t filter -A INPUT -s 192.168.1.150/32 -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
然后保存规则,重启iptables
[root@linux-node1 ~]# service iptables save
[root@linux-node1 ~]# service iptables restart
或者在/etc/sysconfig/iptables文件里设置如下(其实上面在终端命令行里设置并save和restart防火墙后,就会自动保存规则到/etc/sysconfig/iptables这个文件中的):
[root@bastion-IDC ~]# cat /etc/sysconfig/iptables
......
*filter
:INPUT ACCEPT [442620:173026884]
:FORWARD ACCEPT [118911:23993940]
:OUTPUT ACCEPT [8215384:539509656]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -s 192.168.1.0/24 -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A INPUT -s 192.168.1.150/32 -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
[root@bastion-IDC ~]# service iptables restart
2)NAT转发设置
比如访问本机(192.168.1.7)的8088端口转发到192.168.1.160的80端口;访问本机的33066端口转发到192.168.1.161的3306端口
将本机的 7777 端口转发到 6666 端口。
iptables -t nat -A PREROUTING -p tcp --dport 7777 -j REDIRECT --to-port 6666
1.242 机器上将 7777 端口转发到 6666,并侦听 6666 端口。
1.237 机器上连接 1.242 的 7777 端口,虽然 1.242 的 7777 端口并未被侦听,但是被转发给了处于侦听状态的 6666 端口。
1.237 上查看连接信息
1.242 上查看连接信息

ref:https://blog.csdn.net/zhouguoqionghai/article/details/81947603
准备工作:
本机打开ip_forword路由转发功能;192.168.1.160/161的内网网关要和本机网关一致!如果没有内网网关,就将网关设置成本机内网ip,并且关闭防火墙(防火墙要是打开了,就设置对应端口允许本机访问)
[root@kvm-server conf]# iptables -t nat -A PREROUTING -p tcp -m tcp --dport 8088 -j DNAT --to-destination 192.168.1.160:80
[root@kvm-server conf]# iptables -t nat -A POSTROUTING -d 192.168.1.160/32 -p tcp -m tcp --sport 80 -j SNAT --to-source 192.168.1.7
[root@kvm-server conf]# iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 8088 -j ACCEPT
[root@kvm-server conf]# iptables -t nat -A PREROUTING -p tcp -m tcp --dport 33066 -j DNAT --to-destination 192.168.1.161:3306
[root@kvm-server conf]# iptables -t nat -A POSTROUTING -d 192.168.1.161/32 -p tcp -m tcp --sport 3306 -j SNAT --to-source 192.168.1.7
[root@kvm-server conf]# iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 33066 -j ACCEPT
[root@kvm-server conf]# service iptables save
[root@kvm-server conf]# service iptables restart
或者在/etc/sysconfig/iptables文件里设置如下
[root@bastion-IDC ~]# cat /etc/sysconfig/iptables
......
*nat
:PREROUTING ACCEPT [60:4250]
:INPUT ACCEPT [31:1973]
:OUTPUT ACCEPT [3:220]
:POSTROUTING ACCEPT [3:220]
-A PREROUTING -p tcp -m tcp --dport 8088 -j DNAT --to-destination 192.168.1.160:80 //PREROUTING规则都放在上面
-A PREROUTING -p tcp -m tcp --dport 33066 -j DNAT --to-destination 192.168.1.161:3306
-A POSTROUTING -d 192.168.1.160/32 -p tcp -m tcp --sport 80 -j SNAT --to-source 192.168.1.7 //POSTROUTING规则都放在下面
-A POSTROUTING -d 192.168.1.161/32 -p tcp -m tcp --sport 3306 -j SNAT --to-source 192.168.1.7
.....
*filter
:INPUT ACCEPT [16:7159]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [715:147195]
-A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A INPUT -p icmp -j ACCEPT
-A INPUT -i lo -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 8088 -j ACCEPT
-A INPUT -p tcp -m state --state NEW -m tcp --dport 33066 -j ACCEPT
.....
[root@bastion-IDC ~]# service iptables restart
[root@bastion-IDC ~]# iptables -L //列出设置的规则,默认列出的是filter表下的规则
[root@bastion-IDC ~]# iptables -L -t nat //如果列出nat表下规则,就加-t参数
--------------------------------------------------------------------------------------------------------------------------
删除INPUT链的第一条规则
iptables -D INPUT 1
拒绝进入防火墙的所有ICMP协议数据包
iptables -I INPUT -p icmp -j REJECT
允许防火墙转发除ICMP协议以外的所有数据包
iptables -A FORWARD -p ! icmp -j ACCEPT
说明:使用“!”可以将条件取反
拒绝转发来自192.168.1.10主机的数据,允许转发来自192.168.1.0/24网段的数据
iptables -A FORWARD -s 192.168.1.11 -j REJECT
iptables -A FORWARD -s 192.168.1.0/24 -j ACCEPT
说明:注意一定要把拒绝的放在前面不然就不起作用了!
丢弃从外网接口(eth1)进入防火墙本机的源地址为私网地址的数据包
iptables -A INPUT -i eth1 -s 192.168.0.0/16 -j DROP
iptables -A INPUT -i eth1 -s 172.16.0.0/12 -j DROP
iptables -A INPUT -i eth1 -s 10.0.0.0/8 -j DROP
封堵网段(192.168.1.0/24),两小时后解封
# iptables -I INPUT -s 10.20.30.0/24 -j DROP
# iptables -I FORWARD -s 10.20.30.0/24 -j DROP
# at now 2 hours at> iptables -D INPUT 1 at> iptables -D FORWARD 1
说明:这个策略可以借助crond计划任务来完成,就再好不过了
只允许管理员从202.13.0.0/16网段使用SSH远程登录防火墙主机
iptables -A INPUT -s 202.13.0.0/16 -p tcp -m tcp -m state --state NEW --dport 22 -j ACCEPT
说明:这个用法比较适合对设备进行远程管理时使用,比如位于分公司中的SQL服务器需要被总公司的管理员管理时
通常在服务器上会对某一服务端口的访问做白名单限制,比如(其他端口设置和下面一致):
运行本机的3306端口(mysql服务)被访问
iptables -A INPUT -p tcp -m tcp -m state --state NEW --dport 3306 -j ACCEPT
或者只运行本机的3306端口被192.168.1.0/24网段机器访问
iptables -A INPUT -s 192.168.1.0/24 -p tcp -m tcp -m state --state NEW --dport 3306 -j ACCEPT
允许本机开放从TCP端口20-1024提供的应用服务
iptables -A INPUT -p tcp -m tcp -m state --state NEW --dport 20:1024 -j ACCEPT
允许转发来自192.168.0.0/24局域网段的DNS解析请求数据包
iptables -A FORWARD -s 192.168.0.0/24 -p udp --dport 53 -j ACCEPT
iptables -A FORWARD -d 192.168.0.0/24 -p udp --sport 53 -j ACCEPT
屏蔽指定的IP地址
以下规则将屏蔽BLOCK_THIS_IP所指定的IP地址访问本地主机:
BLOCK_THIS_IP="x.x.x.x"
iptables -A INPUT -i eth0 -s "$BLOCK_THIS_IP" -j DROP
(或者仅屏蔽来自该IP的TCP数据包)
iptables -A INPUT -i eth0 -p tcp -s "$BLOCK_THIS_IP" -j DROP
屏蔽环回(loopback)访问
iptables -A INPUT -i lo -j DROP
iptables -A OUTPUT -o lo -j DROP
屏蔽来自外部的ping,即禁止外部机器ping本机
iptables -A INPUT -p icmp --icmp-type echo-request -j DROP
iptables -A OUTPUT -p icmp --icmp-type echo-reply -j DROP
屏蔽从本机ping外部主机,禁止本机ping外部机器
iptables -A OUTPUT -p icmp --icmp-type echo-request -j DROP
iptables -A INPUT -p icmp --icmp-type echo-reply -j DROP
禁止其他主机ping本机,但是允许本机ping其他主机(禁止别人ping本机,也可以使用echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all)
iptables -I INPUT -p icmp --icmp-type echo-request -j DROP
iptables -I INPUT -p icmp --icmp-type echo-reply -j ACCEPT
iptables -I INPUT -p icmp --icmp-type destination-Unreachable -j ACCEPT
禁止转发来自MAC地址为00:0C:29:27:55:3F的和主机的数据包
iptables -A FORWARD -m mac --mac-source 00:0c:29:27:55:3F -j DROP
说明:iptables中使用“-m 模块关键字”的形式调用显示匹配。咱们这里用“-m mac –mac-source”来表示数据包的源MAC地址
允许防火墙本机对外开放TCP端口20、21、25、110以及被动模式FTP端口1250-1280
iptables -A INPUT -p tcp -m multiport --dport 20,21,25,110,1250:1280 -j ACCEPT
注意:这里用“-m multiport --dport”来指定多个目的端口
iptables -A INPUT -p tcp -m tcp -m multiport --dports 22,80,443,1250-1280 -m state --state NEW -j ACCEPT
也可以将这几个端口分开设置多行:
iptables -A INPUT -p tcp -m tcp -m state --state NEW --dport 22 -j ACCEPT
iptables -A INPUT -p tcp -m tcp -m state --state NEW --dport 80 -j ACCEPT
iptables -A INPUT -p tcp -m tcp -m state --state NEW --dport 443 -j ACCEPT
iptables -A INPUT -p tcp -m tcp -m state --state NEW --dport 1250:1280 -j ACCEPT
禁止转发源IP地址为192.168.1.20-192.168.1.99的TCP数据包
iptables -A FORWARD -p tcp -m iprange --src-range 192.168.1.20-192.168.1.99 -j DROP
说明:
此处用“-m iprange --src-range”指定IP范围
1)过滤源地址范围:
iptables -A INPUT -m iprange --src-range 192.168.1.2-192.168.1.7 -j DROP
2)过滤目标地址范围:
iptables -A INPUT -m iprange --dst-range 192.168.1.2-192.168.1.7 -j DROP
3)针对端口访问的过滤。下面表示除了192.168.1.5-192.168.1.10之间的ip能访问192.168.1.67机器的80端口以外,其他ip都不可以访问!
iptables -A INPUT -d 192.168.1.67 -p tcp --dport 80 -m iprange --src-range 192.168.1.5-192.168.1.10 -j ACCEPT
禁止转发与正常TCP连接无关的非--syn请求数据包
iptables -A FORWARD -m state --state NEW -p tcp ! --syn -j DROP
说明:“-m state”表示数据包的连接状态,“NEW”表示与任何连接无关的
拒绝访问防火墙的新数据包,但允许响应连接或与已有连接相关的数据包
iptables -A INPUT -p tcp -m state --state NEW -j DROP
iptables -A INPUT -p tcp -m state --state ESTABLISHED,RELATED -j ACCEPT
说明:“ESTABLISHED”表示已经响应请求或者已经建立连接的数据包,“RELATED”表示与已建立的连接有相关性的,比如FTP数据连接等
防止DoS攻击
iptables -A INPUT -p tcp --dport 80 -m limit --limit 25/minute --limit-burst 100 -j ACCEPT
-m limit: 启用limit扩展,限制速度。
--limit 25/minute: 允许最多每分钟25个连接
--limit-burst 100: 当达到100个连接后,才启用上述25/minute限制
--icmp-type 8 表示 Echo request——回显请求(Ping请求)。下面表示本机ping主机192.168.1.109时候的限速设置:
iptables -I INPUT -d 192.168.1.109 -p icmp --icmp-type 8 -m limit --limit 3/minute --limit-burst 5 -j ACCEPT
允许路由
如果本地主机有两块网卡,一块连接内网(eth0),一块连接外网(eth1),那么可以使用下面的规则将eth0的数据路由到eht1:
iptables -A FORWARD -i eth0 -o eth1 -j ACCEPT
IPtables中可以灵活的做各种网络地址转换(NAT)
网络地址转换主要有两种:SNAT和DNAT
1)SNAT是source network address translation的缩写,即源地址目标转换。
比如,多个PC机使用ADSL路由器共享上网,每个PC机都配置了内网IP。PC机访问外部网络的时候,路由器将数据包的报头中的源地址替换成路由器的ip,当外部网络的服务器比如网站web服务器接到访问请求的时候,它的日志记录下来的是路由器的ip地址,而不是pc机的内网ip,这是因为,这个服务器收到的数据包的报头里边的“源地址”,已经被替换了。所以叫做SNAT,基于源地址的地址转换
2)DNAT是destination network address translation的缩写,即目标网络地址转换。
典型的应用是,有个web服务器放在内网中,配置了内网ip,前端有个防火墙配置公网ip,互联网上的访问者使用公网ip来访问这个网站。
当访问的时候,客户端发出一个数据包,这个数据包的报头里边,目标地址写的是防火墙的公网ip,防火墙会把这个数据包的报头改写一次,将目标地址改写成web服务器的内网ip,然后再把这个数据包发送到内网的web服务器上。这样,数据包就穿透了防火墙,并从公网ip变成了一个对内网地址的访问了。即DNAT,基于目标的网络地址转换
以下规则将会把本机192.168.1.17来自422端口的流量转发到22端口,这意味着来自422端口的SSH连接请求与来自22端口的请求等效。
1)启用DNAT转发
iptables -t nat -A PREROUTING -p tcp -d 192.168.1.17 --dport 422 -j DNAT --to-destination 192.168.1.17:22
2)允许连接到422端口的请求
iptables -t filter -A INPUT -p tcp -m tcp -m state --state NEW --dport 422 -j ACCEPT
3)保存规则
# service iptables save
# service iptables restart
假设现在本机外网网关是58.68.250.1,那么把HTTP请求转发到内部的一台服务器192.168.1.20的8888端口上,规则如下:
iptables -t nat -A PREROUTING -p tcp -i eth0 -d 58.68.250.1 --dport 8888 -j DNAT --to 192.168.1.20:80
iptables -A FORWARD -p tcp -i eth0 -d 192.168.0.2 --dport 80 -j ACCEPT
iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
service iptables save
service iptables restart
或者或本机内网ip是192.168.1.10,那么把HTTP请求转发到内部的一台服务器192.168.1.20的8888端口上,规则如下:
准备工作:本机打开ip_forword路由转发功能;192.168.1.20的内网网关要和本机网关保持一致!如果没有内网网关,就将网关地址设置成本机内网ip,并且关闭防火墙(防火墙要是打开了,就设置对应端口允许本机访问)
iptables -t nat -A PREROUTING -p tcp -m tcp --dport 20022 -j DNAT --to-destination 192.168.1.150:22
iptables -t nat -A POSTROUTING -d 192.168.1.150/32 -p tcp -m tcp --sport 22 -j SNAT --to-source 192.168.1.8
iptables -t filter -A INPUT -p tcp -m state --state NEW -m tcp --dport 20022 -j ACCEPT
service iptables save
service iptables restart
MASQUERADE,地址伪装,在iptables中有着和SNAT相近的效果,但也有一些区别:
1)使用SNAT的时候,出口ip的地址范围可以是一个,也可以是多个,例如:
1)如下命令表示把所有10.8.0.0网段的数据包SNAT成192.168.5.3的ip然后发出去
iptables -t nat -A POSTROUTING -s 10.8.0.0/255.255.255.0 -o eth0 -j SNAT --to-source 192.168.5.3
2)如下命令表示把所有10.8.0.0网段的数据包SNAT成192.168.5.3/192.168.5.4/192.168.5.5等几个ip然后发出去
iptables -t nat -A POSTROUTING -s 10.8.0.0/255.255.255.0 -o eth0 -j SNAT --to-source 192.168.5.3-192.168.5.5
这就是SNAT的使用方法,即可以NAT成一个地址,也可以NAT成多个地址。但是,对于SNAT,不管是几个地址,必须明确的指定要SNAT的ip!
假如当前系统用的是ADSL动态拨号方式,那么每次拨号,出口ip192.168.5.3都会改变,而且改变的幅度很大,不一定是192.168.5.3到192.168.5.5范围内的地址。这个时候如果按照现在的方式来配置iptables就会出现问题了,因为每次拨号后,服务器地址都会变化,而iptables规则内的ip是不会随着自动变化的,每次地址变化后都必须手工修改一次iptables,把规则里边的固定ip改成新的ip,这样是非常不好用的!
2)MASQUERADE就是针对上述场景而设计的,它的作用是,从服务器的网卡上,自动获取当前ip地址来做NAT。
比如下边的命令:
iptables -t nat -A POSTROUTING -s 10.8.0.0/255.255.255.0 -o eth0 -j MASQUERADE
如此配置的话,不用指定SNAT的目标ip了。
不管现在eth0的出口获得了怎样的动态ip,MASQUERADE会自动读取eth0现在的ip地址然后做SNAT出去
这样就实现了很好的动态SNAT地址转换
再看看几个运维实例设置:
1)限制本机的web服务器在周一不允许访问;
新请求的速率不能超过100个每秒;
web服务器包含了admin字符串的页面不允许访问:
web 服务器仅允许响应报文离开本机;
设置如下:
周一不允许访问
iptables -A INPUT -p tcp --dport 80 -m time ! --weekdays Mon -j ACCEPT
iptables -A OUTPUT -p tcp --dport 80 -m state --state ESTABLISHED -j ACCEPT
新请求速率不能超过100个每秒
iptables -A INPUT -p tcp --dport 80 -m limit --limit 100/s -j ACCEPT
web包含admin字符串的页面不允许访问,源端口:dport
iptables -A INPUT -p tcp --dport 80 -m string --algo bm --string 'admin' -j REJECT
web服务器仅允许响应报文离开主机,放行端口(目标端口):sport
iptables -A OUTPUT -p tcp --dport 80 -m state --state ESTABLISHED -j ACCEPT
2)在工作时间,即周一到周五的8:30-18:00,开放本机的ftp服务给 192.168.1.0网络中的主机访问;
数据下载请求的次数每分钟不得超过 5 个;
设置如下:
iptables -A INPUT -p tcp --dport 21 -s 192.168.1.0/24 -m time ! --weekdays 6,7 -m time --timestart 8:30 --timestop 18:00 -m connlimit --connlimit-above 5 -j ACCET
3)开放本机的ssh服务给192.168.1.1-192.168.1.100 中的主机;
新请求建立的速率一分钟不得超过2个;
仅允许响应报文通过其服务端口离开本机;
设置如下:
iptables -A INPUT -p tcp --dport 22 -m iprange --src-rang 192.168.1.1-192.168.1.100 -m limit --limit 2/m -j ACCEPT
iptables -A OUTPUT -p tcp --sport 22 -m iprange --dst-rang 192.168.1.1-192.168.1.100 -m state --state ESTABLISHED -j ACCEPT
4)拒绝 TCP 标志位全部为 1 及全部为 0 的报文访问本机;
iptables -A INPUT -p tcp --tcp-flags ALL ALL -j DROP
5)允许本机 ping 别的主机;但不开放别的主机 ping 本机;
iptables -I INPUT -p icmp --icmp-type echo-request -j DROP
iptables -I INPUT -p icmp --icmp-type echo-reply -j ACCEPT
iptables -I INPUT -p icmp --icmp-type destination-Unreachable -j ACCEPT
或者下面禁ping操作:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
ref:https://www.cnblogs.com/kevingrace/p/6265113.html
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
iptables配置文件
直接改iptables配置就可以了:vim /etc/sysconfig/iptables。
1、关闭所有的 INPUT FORWARD OUTPUT 只对某些端口开放。
下面是命令实现:
iptables -P INPUT DROP
iptables -P FORWARD DROP
iptables -P OUTPUT DROP
再用命令 iptables -nvL 查看 是否设置好, 好看到全部 DROP 了
这样的设置好了,我们只是临时的, 重启服务器还是会恢复原来没有设置的状态
还要使用 service iptables save 进行保存
看到信息 firewall rules 防火墙的规则 其实就是保存在 /etc/sysconfig/iptables
可以打开文件查看 vi /etc/sysconfig/iptables
2、
下面我只打开22端口,看我是如何操作的,就是下面2个语句(一下为命令行模式)
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
再查看下 iptables -nvL 是否添加上去, 看到添加了
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
Chain FORWARD (policy DROP)
target prot opt source destination
Chain OUTPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:22
现在Linux服务器只打开了22端口,用putty.exe测试一下是否可以链接上去。
可以链接上去了,说明没有问题。
最后别忘记了保存 对防火墙的设置
通过命令:service iptables save 进行保存
重启iptables
service iptables save && service iptables restart
关闭防火墙
chkconfig iptables off && service iptables stop
iptables -A INPUT -p tcp --dport 22 -j ACCEPT
iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
针对这2条命令进行一些讲解吧
-A 参数就看成是添加一条 INPUT 的规则
-p 指定是什么协议 我们常用的tcp 协议,当然也有udp 例如53端口的DNS
到时我们要配置DNS用到53端口 大家就会发现使用udp协议的
而 --dport 就是目标端口 当数据从外部进入服务器为目标端口
反之 数据从服务器出去 则为数据源端口 使用 --sport
-j 就是指定是 ACCEPT 接收 或者 DROP 不接收
3、禁止某个IP访问
1台Linux服务器,2台windows xp 操作系统进行访问
Linux服务器ip 192.168.1.99
xp1 ip: 192.168.1.2
xp2 ip: 192.168.1.8
下面看看我2台xp 都可以访问的
192.168.1.2 这是 xp1 可以访问的,
192.168.1.8 xp2 也是可以正常访问的。
那么现在我要禁止 192.168.1.2 xp1 访问, xp2 正常访问,
下面看看演示
通过命令 iptables -A INPUT -p tcp -s 192.168.1.2 -j DROP
这里意思就是 -A 就是添加新的规则, 怎样的规则呢? 由于我们访问网站使用tcp的,
我们就用 -p tcp , 如果是 udp 就写udp,这里就用tcp了, -s就是 来源的意思,
ip来源于 192.168.1.2 ,-j 怎么做 我们拒绝它 这里应该是 DROP
好,看看效果。好添加成功。下面进行验证 一下是否生效
一直出现等待状态 最后 该页无法显示 ,这是 192.168.1.2 xp1 的访问被拒绝了。
再看看另外一台 xp 是否可以访问, 是可以正常访问的 192.168.1.8 是可以正常访问的
4、如何删除规则
首先我们要知道 这条规则的编号,每条规则都有一个编号
通过 iptables -nvL --line-numbers 可以显示规则和相对应的编号
num target prot opt source destination
1 DROP tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:3306
2 DROP tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:21
3 DROP tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
多了 num 这一列, 这样我们就可以 看到刚才的规则对应的是 编号2
那么我们就可以进行删除了
iptables -D INPUT 2
删除INPUT链编号为2的规则。
再 iptables -nvL 查看一下 已经被清除了。
5、过滤无效的数据包
假设有人进入了服务器,或者有病毒木马程序,它可以通过22,80端口像服务器外传送数据。
它的这种方式就和我们正常访问22,80端口区别。它发向外发的数据不是我们通过访问网页请求
而回应的数据包。
下面我们要禁止这些没有通过请求回应的数据包,统统把它们堵住掉。
iptables 提供了一个参数 是检查状态的,下面我们来配置下 22 和 80 端口,防止无效的数据包。
iptables -A OUTPUT -p tcp --sport 22 -m state --state ESTABLISHED -j ACCEPT
可以看到和我们以前使用的:
iptables -A OUTPUT -p tcp --sport 22 -j ACCEPT
多了一个状态判断。
同样80端口也一样, 现在删掉原来的2条规则,
iptables -nvL --line-numbers 这个是查看规则而且带上编号。我们看到编号就可以
删除对应的规则了。
iptables -D OUTPUT 1 这里的1表示第一条规则。
当你删除了前面的规则, 编号也会随之改变。看到了吧。
好,我们删除了前面2个规则,22端口还可以正常使用,说明没问题了
下面进行保存,别忘记了,不然的话重启就会还原到原来的样子。
service iptables save 进行保存。
Saving firewall rules to /etc/sysconfig/iptables: [ OK ]
其实就是把刚才设置的规则写入到 /etc/sysconfig/iptables 文件中。
6、DNS端口53设置
下面我们来看看如何设置iptables来打开DNS端口,DNS端口对应的是53
大家看到我现在的情况了吧,只开放22和80端口, 我现在看看能不能解析域名。
host www.google.com 输入这个命令后,一直等待,说明DNS不通
出现下面提示 :
;; connection timed out; no servers could be reached
ping 一下域名也是不通
[root@localhost ~ping www.google.com
ping: unknown host www.google.com
我这里的原因就是 iptables 限制了53端口。
有些服务器,特别是Web服务器减慢,DNS其实也有关系的,无法发送包到DNS服务器导致的。
下面演示下如何使用 iptables 来设置DNS 53这个端口,如果你不知道 域名服务端口号,你
可以用命令 : grep domain /etc/services
[root@localhost ~grep domain /etc/services
domain 53/tcp # name-domain server
domain 53/udp
domaintime 9909/tcp # domaintime
domaintime 9909/udp # domaintime
看到了吧, 我们一般使用 udp 协议。
好了, 开始设置。。。
iptables -A OUTPUT -p udp --dport 53 -j ACCEPT
这是我们 ping 一个域名,数据就是从本机出去,所以我们先设置 OUTPUT,
我们按照ping这个流程来设置。
然后 DNS 服务器收到我们发出去的包,就回应一个回来
iptables -A INPUT -p udp --sport 53 -j ACCEPT
同时还要设置
iptables -A INPUT -p udp --dport 53 -j ACCEPT
iptables -A OUTPUT -p udp --sport 53 -j ACCEPT
好了, 下面开始测试下, 可以用 iptables -nvL 查看设置情况,确定没有问题就可以测试了
[root@localhost ~iptables -nvL
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp spt:53
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:53
Chain FORWARD (policy DROP)
target prot opt source destination
Chain OUTPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:22 state ESTABLISHED
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:80 state ESTABLISHED
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp dpt:53
ACCEPT udp -- 0.0.0.0/0 0.0.0.0/0 udp spt:53
可以测试一下 是否 DNS 可以通过iptables 了。
[root@localhost ~host www.google.com
www.google.com is an alias for www.l.google.com.
www.l.google.com is an alias for www-china.l.google.com.
www-china.l.google.com has address 64.233.189.104
www-china.l.google.com has address 64.233.189.147
www-china.l.google.com has address 64.233.189.99
正常可以解析 google 域名。
ping 方面可能还要设置些东西。
用 nslookup 看看吧
[root@localhost ~nslookup
> www.google.com
Server: 192.168.1.1
Address: 192.168.1.1#53
Non-authoritative answer:
www.google.com canonical name = www.l.google.com.
www.l.google.com canonical name = www-china.l.google.com.
Name: www-china.l.google.com
Address: 64.233.189.147
Name: www-china.l.google.com
Address: 64.233.189.99
Name: www-china.l.google.com
Address: 64.233.189.104
说明本机DNS正常, iptables 允许53这个端口的访问。
7、iptables对ftp的设置
现在我开始对ftp端口的设置,按照我们以前的视频,添加需要开放的端口
ftp连接端口有2个 21 和 20 端口,我现在添加对应的规则。
[root@localhost rootiptables -A INPUT -p tcp --dport 21 -j ACCEPT
[root@localhost rootiptables -A INPUT -p tcp --dport 20 -j ACCEPT
[root@localhost rootiptables -A OUTPUT -p tcp --sport 21 -j ACCEPT
[root@localhost rootiptables -A OUTPUT -p tcp --sport 20 -j ACCEPT
好,这样就添加完了,我们用浏览器访问一下ftp,出现超时。
所以我刚才说 ftp 是比较特殊的端口,它还有一些端口是 数据传输端口,
例如目录列表, 上传 ,下载 文件都要用到这些端口。
而这些端口是 任意 端口。。。 这个 任意 真的比较特殊。
如果不指定什么一个端口范围, iptables 很难对任意端口开放的,
如果iptables允许任意端口访问, 那和不设置防火墙没什么区别,所以不现实的。
那么我们的解决办法就是 指定这个数据传输端口的一个范围。
下面我们修改一下ftp配置文件。
我这里使用vsftpd来修改演示,其他ftp我不知道哪里修改,大家可以找找资料。
[root@localhost rootvi /etc/vsftpd.conf
在配置文件的最下面 加入
pasv_min_port=30001
pasv_max_port=31000
然后保存退出。
这两句话的意思告诉vsftpd, 要传输数据的端口范围就在30001到31000 这个范围内传送。
这样我们使用 iptables 就好办多了,我们就打开 30001到31000 这些端口。
[root@localhost rootiptables -A INPUT -p tcp --dport 30001:31000 -j ACCEPT
[root@localhost rootiptables -A OUTPUT -p tcp --sport 30001:31000 -j ACCEPT
[root@localhost rootservice iptables save
最后进行保存, 然后我们再用浏览器范围下 ftp。可以正常访问
用个账号登陆上去,也没有问题,上传一些文件上去看看。
看到了吧,上传和下载都正常。。 再查看下 iptables 的设置
[root@localhost root# iptables -nvL
Chain INPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:21
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:20
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpts:30001:31000
Chain FORWARD (policy DROP)
target prot opt source destination
Chain OUTPUT (policy DROP)
target prot opt source destination
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:22
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:21
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:20
ACCEPT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spts:30001:31000
这是我为了演示ftp特殊端口做的简单规则,大家可以添加一些对数据包的验证
例如 -m state --state ESTABLISHED,RELATED 等等要求更加高的验证
例子1:
iptables -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
#如上例,添加一条入站规则:对进来的包的状态进行检测。已经建立tcp连接的包以及该连接相关的包允许通过!
#ESTABLISHED:已建立的链接状态。RELATED:该数据包与本机发出的数据包有关。
例子2:
iptables -A INPUT -i lo -j ACCEPT
#-i 参数是指定接口,这里的接口是lo ,lo就是Loopback(本地环回接口),意思就允许本地环回接口在INPUT表的所有数据通信。
例子3:
-A INPUT -j REJECT --reject-with icmp-host-prohibited搜索
-A FORWARD -j REJECT --reject-with icmp-host-prohibited
# 这两条的意思是在INPUT表和FORWARD表中拒绝所有其他不符合上述任何一条规则的数据包。并且发送一条host prohibited的消息给被拒绝的主机。(一般不发送,就不添加这两条)
以下是iptables相关命令和参数:
ilter 这个规则表是预设规则表,拥有 INPUT、FORWARD 和 OUTPUT 三个规则链,这个规则表顾名思义是用来进行封包过滤的理动作(例如:DROP、 LOG、 ACCEPT 或 REJECT),我们会将基本规则都建立在此规则表中。
主要包含:命令表
用来增加(-A、-I)删除(-D)修改(-R)查看(-L)规则等;
常用参数 用来指定协议(-p)、源地址(-s)、源端口(--sport)、目的地址(-d)、目的端口(--dport)、
进入网卡(-i)、出去网卡(-o)等设定包信息(即什么样的包); 用来描述要处理包的信息。
常用处理动作 用 -j 来指定对包的处理(ACCEPT、DROP、REJECT、REDIRECT等)。
1、常用命令列表: 常用命令(-A追加规则、-D删除规则、-R修改规则、-I插入规则、-L查看规则)
命令 -A, --append
范例 iptables -A INPUT ...
说明 新增规则(追加方式)到某个规则链(这里是INPUT规则链)中,该规则将会成为规则链中的最后一条规则。
命令 -D, --delete
范例 iptables -D INPUT --dport 80 -j DROP
iptables -D INPUT 1
说明 从某个规则链中删除一条规则,可以输入完整规则,或直接指定规则编号加以删除。
命令 -R, --replace
范例 iptables -R INPUT 1 -s 192.168.0.1 -j DROP
说明 取代现行规则,规则被取代后并不会改变顺序。(1是位置)
命令 -I, --insert
范例 iptables -I INPUT 1 --dport 80 -j ACCEPT
说明 插入一条规则,原本该位置(这里是位置1)上的规则将会往后移动一个顺位。
命令 -L, --list
范例 iptables -L INPUT
说明 列出某规则链中的所有规则。
命令 -F, --flush
范例 iptables -F INPUT
说明 删除某规则链(这里是INPUT规则链)中的所有规则。
命令 -Z, --zero
范例 iptables -Z INPUT
说明 将封包计数器归零。封包计数器是用来计算同一封包出现次数,是过滤阻断式攻击不可或缺的工具。
命令 -N, --new-chain
范例 iptables -N allowed
说明 定义新的规则链。
命令 -X, --delete-chain
范例 iptables -X allowed
说明 删除某个规则链。
命令 -P, --policy
范例 iptables -P INPUT DROP
说明 定义过滤政策。 也就是未符合过滤条件之封包,预设的处理方式。
命令 -E, --rename-chain
范例 iptables -E allowed disallowed
说明 修改某自订规则链的名称。
2、常用封包比对参数:(-p协议、-s源地址、-d目的地址、--sport源端口、--dport目的端口、-i 进入网卡、-o 出去网卡)
参数 -p, --protocol (指定协议)
范例 iptables -A INPUT -p tcp (指定协议) -p all 所有协议, -p !tcp 去除tcp外的所有协议。
说明 比对通讯协议类型是否相符,可以使用 ! 运算子进行反向比对,例如:-p ! tcp ,
意思是指除 tcp 以外的其它类型,包含udp、icmp ...等。如果要比对所有类型,则可以使用 all 关键词,例如:-p all。
参数 -s, --src, --source (指定源地址,指定源端口--sport)
例如: iptables -A INPUT -s 192.168.1.1
说明 用来比对封包的来源 IP,可以比对单机或网络,比对网络时请用数字来表示屏蔽,
例如:-s 192.168.0.0/24,比对 IP 时可以使用 ! 运算子进行反向比对,
例如:-s ! 192.168.0.0/24。
参数 -d, --dst, --destination (指定目的地址,指定目的端口--dport)
例如: iptables -A INPUT -d 192.168.1.1
说明 用来比对封包的目的地 IP,设定方式同上。
参数 -i, --in-interface (指定入口网卡) -i eth+ 所有网卡
例如: iptables -A INPUT -i eth0
说明 用来比对封包是从哪片网卡进入,可以使用通配字符 + 来做大范围比对,
例如:-i eth+ 表示所有的 ethernet 网卡,也以使用 ! 运算子进行反向比对,
例如:-i ! eth0。
参数 -o, --out-interface (指定出口网卡)
例如: iptables -A FORWARD -o eth0
说明 用来比对封包要从哪片网卡送出,设定方式同上。
参数 --sport, --source-port (源端口)
例如: iptables -A INPUT -p tcp --sport 22
说明 用来比对封包的来源端口号,可以比对单一埠,或是一个范围,
例如:--sport 22:80,表示从 22 到 80 端口之间都算是符合件,
如果要比对不连续的多个埠,则必须使用 --multiport 参数,详见后文。比对埠号时,可以使用 ! 运算子进行反向比对。
参数 --dport, --destination-port (目的端口)
例如: iptables -A INPUT -p tcp --dport 22
说明 用来比对封包的目的端口号,设定方式同上。
参数 --tcp-flags (只过滤TCP中的一些包,比如SYN包,ACK包,FIN包,RST包等等)
例如: iptables -p tcp --tcp-flags SYN,FIN,ACK SYN
说明 比对 TCP 封包的状态旗号,参数分为两个部分,第一个部分列举出想比对的旗号,
第二部分则列举前述旗号中哪些有被设,未被列举的旗号必须是空的。TCP 状态旗号包括:SYN(同步)、ACK(应答)、
FIN(结束)、RST(重设)、URG(紧急)PSH(强迫推送) 等均可使用于参数中,除此之外还可以使用关键词 ALL 和
NONE 进行比对。比对旗号时,可以使用 ! 运算子行反向比对。
参数 --syn
例如: iptables -p tcp --syn
说明 用来比对是否为要求联机之 TCP 封包,与 iptables -p tcp --tcp-flags SYN,
FIN,ACK SYN 的作用完全相同,如果使用 !运算子,可用来比对非要求联机封包。
参数 -m multiport --source-port
例如: iptables -A INPUT -p tcp -m multiport --source-port 22,53,80,110
说明 用来比对不连续的多个来源埠号,一次最多可以比对 15 个埠,可以使用 !
运算子进行反向比对。
参数 -m multiport --destination-port
例如: iptables -A INPUT -p tcp -m multiport --destination-port 22,53,80,110
说明 用来比对不连续的多个目的地埠号,设定方式同上。
参数 -m multiport --port
例如: iptables -A INPUT -p tcp -m multiport --port 22,53,80,110
说明 这个参数比较特殊,用来比对来源埠号和目的埠号相同的封包,设定方式同上。
注意:在本范例中,如果来源端口号为 80目的地埠号为 110,这种封包并不算符合条件。
参数 --icmp-type
例如: iptables -A INPUT -p icmp --icmp-type 8
说明 用来比对 ICMP 的类型编号,可以使用代码或数字编号来进行比对。
请打 iptables -p icmp --help 来查看有哪些代码可用。
参数 -m limit --limit
例如: iptables -A INPUT -m limit --limit 3/hour
说明 用来比对某段时间内封包的平均流量,上面的例子是用来比对:每小时平均流量是
否超过一次 3 个封包。 除了每小时平均次外,也可以每秒钟、每分钟或每天平均一次,
默认值为每小时平均一次,参数如后: /second、 /minute、/day。 除了进行封数量的
比对外,设定这个参数也会在条件达成时,暂停封包的比对动作,以避免因骇客使用洪水
攻击法,导致服务被阻断。
参数 --limit-burst
范例 iptables -A INPUT -m limit --limit-burst 5
说明 用来比对瞬间大量封包的数量,上面的例子是用来比对一次同时涌入的封包是否超
过 5 个(这是默认值),超过此上限的封将被直接丢弃。使用效果同上。
参数 -m mac --mac-source
范例 iptables -A INPUT -m mac --mac-source 00:00:00:00:00:01
说明 用来比对封包来源网络接口的硬件地址,这个参数不能用在 OUTPUT 和 Postrouting规则炼上,这是因为封包要送出到网后,才能由网卡驱动程序透过 ARP 通讯协议查出目的地的 MAC 地址,所以 iptables 在进行封包比对时,并不知道封包会送到个网络接口去。
参数 --mark
范例 iptables -t mangle -A INPUT -m mark --mark 1
说明 用来比对封包是否被表示某个号码,当封包被比对成功时,我们可以透过 MARK 处理动作,将该封包标示一个号码,号码最不可以超过 4294967296。
参数 -m owner --uid-owner
范例 iptables -A OUTPUT -m owner --uid-owner 500
说明 用来比对来自本机的封包,是否为某特定使用者所产生的,这样可以避免服务器使用
root 或其它身分将敏感数据传送出,可以降低系统被骇的损失。可惜这个功能无法比对出
来自其它主机的封包。
参数 -m owner --gid-owner
范例 iptables -A OUTPUT -m owner --gid-owner 0
说明 用来比对来自本机的封包,是否为某特定使用者群组所产生的,使用时机同上。
参数 -m owner --pid-owner
范例 iptables -A OUTPUT -m owner --pid-owner 78
说明 用来比对来自本机的封包,是否为某特定行程所产生的,使用时机同上。
参数 -m owner --sid-owner
范例 iptables -A OUTPUT -m owner --sid-owner 100
说明 用来比对来自本机的封包,是否为某特定联机(Session ID)的响应封包,使用时
机同上。
参数 -m state --state
范例 iptables -A INPUT -m state --state RELATED,ESTABLISHED
说明 用来比对联机状态,联机状态共有四种:INVALID、ESTABLISHED、NEW 和 RELATED。
INVALID 表示该封包的联机编号(Session ID)无法辨识或编号不正确。
ESTABLISHED 表示该封包属于某个已经建立的联机。
NEW 表示该封包想要起始一个联机(重设联机或将联机重导向)。
RELATED 表示该封包是属于某个已经建立的联机,所建立的新联机。例如:FTP-DATA 联机必定是源自某个 FTP 联机。
3、常用的处理动作: (-j 指定对满足条件包的处理,常用动作有ACCEPT接受报、DROP丢弃报、REJECT丢弃报并通知对方、REDIRECT重定向包等)
-j 参数用来指定要进行的处理动作,常用的处理动作包括:ACCEPT、REJECT、DROP、REDIRECT、MASQUERADE、LOG、DNAT、SNAT、MIRROR、QUEUE、RETURN、MARK,分别说明如下:
ACCEPT 将封包放行,进行完此处理动作后,将不再比对其它规则,直接跳往下一个规则链(natostrouting)。
REJECT 拦阻该封包,并传送封包通知对方,可以传送的封包有几个选择:ICMP port-unreachable、ICMP echo-reply 或是 tcp-reset(这个封包会要求对方关闭联机),进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
例如:iptables -A FORWARD -p TCP --dport 22 -j REJECT --reject-with tcp-reset
DROP 丢弃封包不予处理,进行完此处理动作后,将不再比对其它规则,直接中断过滤程序。
REDIRECT 将封包重新导向到另一个端口(PNAT),进行完此处理动作后,将会继续比对其它规则。
这个功能可以用来实作通透式porxy 或用来保护 web 服务器。
例如:iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-ports 8080
MASQUERADE 改写封包来源 IP 为防火墙 NIC IP,可以指定 port 对应的范围,进行完此处理动作后,直接跳往下一个规则(mangleostrouting)。这个功能与 SNAT 略有不同,当进行 IP 伪装时,不需指定要伪装成哪个 IP,IP 会从网卡直接读,当使用拨接连线时,IP 通常是由 ISP 公司的 DHCP 服务器指派的,这个时候 MASQUERADE 特别有用。
例如:iptables -t nat -A POSTROUTING -p TCP -j MASQUERADE --to-ports 1024-31000
LOG 将封包相关讯息纪录在 /var/log 中,详细位置请查阅 /etc/syslog.conf 组态档,进行完此处理动作后,将会继续比对其规则。
例如:iptables -A INPUT -p tcp -j LOG --log-prefix "INPUT packets"
SNAT 改写封包来源 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将直接跳往下一个规则(mangleostrouting)。
例如:iptables -t nat -A POSTROUTING -p tcp-o eth0 -j SNAT --to-source 194.236.50.155-194.236.50.160:1024-32000
DNAT 改写封包目的地 IP 为某特定 IP 或 IP 范围,可以指定 port 对应的范围,进行完此处理动作后,将会直接跳往下一个规炼(filter:input 或 filter:forward)。
例如:iptables -t nat -A PREROUTING -p tcp -d 15.45.23.67 --dport 80 -j DNAT --to-destination 192.168.1.1-192.168.1.10:80-100
MIRROR 镜射封包,也就是将来源 IP 与目的地 IP 对调后,将封包送回,进行完此处理动作后,将会中断过滤程序。
QUEUE 中断过滤程序,将封包放入队列,交给其它程序处理。透过自行开发的处理程序,可以进行其它应用,
例如:计算联机费......等。
RETURN 结束在目前规则炼中的过滤程序,返回主规则炼继续过滤,如果把自订规则炼看成是一个子程序,那么这个动作,就相当提早结束子程序并返回到主程序中。
MARK 将封包标上某个代号,以便提供作为后续过滤的条件判断依据,进行完此处理动作后,将会继续比对其它规则。
例如:iptables -t mangle -A PREROUTING -p tcp --dport 22 -j MARK --set-mark 2
四.拓展模块
1.按来源MAC地址匹配
# iptables -t filter -A FORWARD -m --mac-source 00:02:b2:03:a5:f6 -j DROP
拒绝转发来自该MAC地址的数据包
2.按多端口或连续端口匹配
20: 表示20以后的所有端口
20:100 表示20到100的端口
:20 表示20之前的所有端口
-m multiport [--prots, --sports,--dports]
例子:
# iptables -A INPUT -p tcp -m multiport --dports 21,20,25,53,80 -j ACCEPT 【多端口匹配】
# iptables -A INPUT -p tcp --dport 20: -j ACCEPT
# iptables -A INPUT -p tcp --sport 20:80 -j ACCEPT
# iptables -A INPUT -p tcp --sport :80 -j ACCEPT
3.还可以按数据包速率和状态匹配
-m limit --limit 匹配速率 如: -m limit --limit 50/s -j ACCEPT
-m state --state 状态 如: -m state --state INVALID,RELATED -j ACCEPT
4.还可以限制链接数
-m connlimit --connlimit-above n 限制为多少个
例如:
iptables -I FORWARD -p tcp -m connlimit --connlimit-above 9 -j DROP //表示限制链接数最大为9个
5、模拟随机丢包率
iptables -A FORWARD -p icmp -m statistic --mode random --probability 0.31 -j REJECT //表示31%的丢包率
或者
-m random --average 5 -j DROP 表示模拟丢掉5%比例的包
相关知识:
设置延时 3s :
tc qdisc add dev eth0 root netem delay 3000ms
可以在 3000ms 后面在加上一个延时,比如 ’3000ms 200ms‘表示 3000ms ± 200ms ,延时范围 2800 – 3200 之间.
结果显示如下
设置丢包 50% ,iptables 也可以模拟这个,但一下不记的命令了,下次放上来:
tc qdisc change dev eth0 root netem loss 50%
上面的设丢包,如果给后面的 50% 的丢包比率修改成 ’50% 80%’ 时,这时和上面的延时不一样,这是指丢包比率为 50-80% 之间。
ref:https://www.cnblogs.com/itxiongwei/p/5871075.html
---------------------------------------------------------------------------------------------------------------------------
用iptables的raw表解决ip_conntrack: table full, dropping packet的问题
1) 什么是raw表?做什么用的?
iptables有5个链:PREROUTING,INPUT,FORWARD,OUTPUT,POSTROUTING,4个表:filter,nat,mangle,raw.
4个表的优先级由高到低的顺序为:raw-->mangle-->nat-->filter
举例来说:如果PRROUTING链上,即有mangle表,也有nat表,那么先由mangle处理,然后由nat表处理
RAW表只使用在PREROUTING链和OUTPUT链上,因为优先级最高,从而可以对收到的数据包在连接跟踪前进行处理。一但用户使用了RAW表,在某个链上,RAW表处理完后,将跳过NAT表和 ip_conntrack处理,即不再做地址转换和数据包的链接跟踪处理了.
RAW表可以应用在那些不需要做nat的情况下,以提高性能。如大量访问的web服务器,可以让80端口不再让iptables做数据包的链接跟踪处理,以提高用户的访问速度。
2) iptables的数据包的流程是怎样的?
(流程介绍来源:)
一个数据包到达时,是怎么依次穿过各个链和表的(图)。
基本步骤如下:
1. 数据包到达网络接口,比如 eth0。
2. 进入 raw 表的 PREROUTING 链,这个链的作用是赶在连接跟踪之前处理数据包。
3. 如果进行了连接跟踪,在此处理。
4. 进入 mangle 表的 PREROUTING 链,在此可以修改数据包,比如 TOS 等。
5. 进入 nat 表的 PREROUTING 链,可以在此做DNAT,但不要做过滤。
6. 决定路由,看是交给本地主机还是转发给其它主机。
到了这里我们就得分两种不同的情况进行讨论了,一种情况就是数据包要转发给其它主机,这时候它会依次经过:
7. 进入 mangle 表的 FORWARD 链,这里也比较特殊,这是在第一次路由决定之后,在进行最后的路由决定之前,我们仍然可以对数据包进行某些修改。
8. 进入 filter 表的 FORWARD 链,在这里我们可以对所有转发的数据包进行过滤。需要注意的是:经过这里的数据包是转发的,方向是双向的。
9. 进入 mangle 表的 POSTROUTING 链,到这里已经做完了所有的路由决定,但数据包仍然在本地主机,我们还可以进行某些修改。
10. 进入 nat 表的 POSTROUTING 链,在这里一般都是用来做 SNAT ,不要在这里进行过滤。
11. 进入出去的网络接口。完毕。
另一种情况是,数据包就是发给本地主机的,那么它会依次穿过:
7. 进入 mangle 表的 INPUT 链,这里是在路由之后,交由本地主机之前,我们也可以进行一些相应的修改。
8. 进入 filter 表的 INPUT 链,在这里我们可以对流入的所有数据包进行过滤,无论它来自哪个网络接口。
9. 交给本地主机的应用程序进行处理。
10. 处理完毕后进行路由决定,看该往那里发出。
11. 进入 raw 表的 OUTPUT 链,这里是在连接跟踪处理本地的数据包之前。
12. 连接跟踪对本地的数据包进行处理。
13. 进入 mangle 表的 OUTPUT 链,在这里我们可以修改数据包,但不要做过滤。
14. 进入 nat 表的 OUTPUT 链,可以对防火墙自己发出的数据做 NAT 。
15. 再次进行路由决定。
16. 进入 filter 表的 OUTPUT 链,可以对本地出去的数据包进行过滤。
17. 进入 mangle 表的 POSTROUTING 链,同上一种情况的第9步。注意,这里不光对经过防火墙的数据包进行处理,还对防火墙自己产生的数据包进行处理。
18. 进入 nat 表的 POSTROUTING 链,同上一种情况的第10步。
19. 进入出去的网络接口。完毕。
3) iptables raw表的使用
增加raw表,在其他表处理之前,-j NOTRACK跳过其它表处理
状态除了以前的四个还增加了一个UNTRACKED
例如:
可以使用 “NOTRACK” target 允许规则指定80端口的包不进入链接跟踪/NAT子系统
iptables -t raw -A PREROUTING -d 1.2.3.4 -p tcp --dport 80 -j NOTRACK
iptables -t raw -A PREROUTING -s 1.2.3.4 -p tcp --sport 80 -j NOTRACK
iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT
4) 解决ip_conntrack: table full, dropping packet的问题
在启用了iptables web服务器上,流量高的时候经常会出现下面的错误:
ip_conntrack: table full, dropping packet
这个问题的原因是由于web服务器收到了大量的连接,在启用了iptables的情况下,iptables会把所有的连接都做链接跟踪处理,这样iptables就会有一个链接跟踪表,当这个表满的时候,就会出现上面的错误。
iptables的链接跟踪表最大容量为/proc/sys/net/ipv4/ip_conntrack_max,链接碰到各种状态的超时后就会从表中删除。
所以解決方法一般有两个:
(1) 加大 ip_conntrack_max 值
vi /etc/sysctl.conf
net.ipv4.ip_conntrack_max = 393216
net.ipv4.netfilter.ip_conntrack_max = 393216
(2): 降低 ip_conntrack timeout时间
vi /etc/sysctl.conf
net.ipv4.netfilter.ip_conntrack_tcp_timeout_established = 300
net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait = 120
net.ipv4.netfilter.ip_conntrack_tcp_timeout_close_wait = 60
net.ipv4.netfilter.ip_conntrack_tcp_timeout_fin_wait = 120
上面两种方法打个比喻就是烧水水开的时候,换一个大锅。一般情况下都可以解决问题,但是在极端情况下,还是不够用,怎么办?
这样就得反其道而行,用釜底抽薪的办法。iptables的raw表是不做数据包的链接跟踪处理的,我们就把那些连接量非常大的链接加入到iptables raw表。
如一台web服务器可以这样:
iptables -t raw -A PREROUTING -d 1.2.3.4 -p tcp --dport 80 -j NOTRACK
iptables -A FORWARD -m state --state UNTRACKED -j ACCEPT
5) iptables raw表的效果测试
我们在一台web server上做测试,先不使用raw表,观察链接跟踪表(/proc/net/ip_conntrack)的大小:
先看下iptables配置:
cat /etc/sysconfig/iptables
# Generated by iptables-save v1.3.5 on Wed Aug 18 10:10:52 2010
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [104076:12500201]
:RH-Firewall-1-INPUT - [0:0]
-A INPUT -j RH-Firewall-1-INPUT
-A FORWARD -j RH-Firewall-1-INPUT
-A RH-Firewall-1-INPUT -i lo -j ACCEPT
-A RH-Firewall-1-INPUT -p icmp -m icmp --icmp-type any -j ACCEPT
-A RH-Firewall-1-INPUT -p esp -j ACCEPT
-A RH-Firewall-1-INPUT -p ah -j ACCEPT
-A RH-Firewall-1-INPUT -d 224.0.0.251 -p udp -m udp --dport 5353 -j ACCEPT
-A RH-Firewall-1-INPUT -p udp -m udp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -j REJECT --reject-with icmp-host-prohibited
COMMIT
# Completed on Wed Aug 18 10:10:52 2010
在另一台机器上用ab测试:
ab -c 1000 -n 5000
在web server上查看链接跟踪表(/proc/net/ip_conntrack)的大小:
[root@mongo html]# wc -l /proc/net/ip_conntrack
5153 /proc/net/ip_conntrack
可以看到跟踪表内有5153个链接,再大一些的压力可能就要报ip_conntrack: table full, dropping packet的错误了。
下面我们启用raw表:
先更新iptables:
[root@mongo html]# cat /etc/sysconfig/iptables
# Generated by iptables-save v1.3.5 on Wed Aug 18 10:10:52 2010
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [104076:12500201]
:RH-Firewall-1-INPUT - [0:0]
-A INPUT -j RH-Firewall-1-INPUT
-A FORWARD -j RH-Firewall-1-INPUT
-A RH-Firewall-1-INPUT -i lo -j ACCEPT
-A RH-Firewall-1-INPUT -p icmp -m icmp --icmp-type any -j ACCEPT
-A RH-Firewall-1-INPUT -p esp -j ACCEPT
-A RH-Firewall-1-INPUT -p ah -j ACCEPT
-A RH-Firewall-1-INPUT -d 224.0.0.251 -p udp -m udp --dport 5353 -j ACCEPT
-A RH-Firewall-1-INPUT -p udp -m udp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m tcp --dport 631 -j ACCEPT
-A RH-Firewall-1-INPUT -m state --state RELATED,ESTABLISHED,UNTRACKED -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
-A RH-Firewall-1-INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT
-A RH-Firewall-1-INPUT -j REJECT --reject-with icmp-host-prohibited
COMMIT
# Completed on Wed Aug 18 10:10:52 2010
# Generated by iptables-save v1.3.5 on Wed Aug 18 10:10:52 2010
*raw
:PREROUTING ACCEPT [116163:9327716]
:OUTPUT ACCEPT [104076:12500201]
-A PREROUTING -p tcp -m tcp --dport 80 -j NOTRACK
-A OUTPUT -p tcp -m tcp --sport 80 -j NOTRACK
COMMIT
# Completed on Wed Aug 18 10:10:52 2010
红色部分是新增的。
重启iptables:
service iptables restart
可以用iptables命令查看是否启用成功了:
[root@mongo html]# iptables -t raw -nvL
Chain PREROUTING (policy ACCEPT)
target prot opt source destination
NOTRACK tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:80
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
NOTRACK tcp -- 0.0.0.0/0 0.0.0.0/0 tcp spt:80
然后再用ab测试:
ab -c 1000 -n 5000
查看链接跟踪表(/proc/net/ip_conntrack)的大小:
[root@mongo html]# wc -l /proc/net/ip_conntrack
1 /proc/net/ip_conntrack
跟踪表内只跟踪了一个链接了。
[root@mongo html]# cat /proc/net/ip_conntrack
tcp 6 431999 ESTABLISHED src=192.168.20.26 dst=192.168.20.10 sport=22 dport=50088 packets=85 bytes=10200 src=192.168.20.10 dst=192.168.20.26 sport=50088 dport=22 packets=92 bytes=6832 [ASSURED] mark=0 secmark=0 use=1
可以看到iptables已经不跟踪进出端口为80的链接了。测试结果表明用iptables的raw表可以完美解决ip_conntrack: table full, dropping packet的问题。
ref:http://blog.chinaunix.net/uid-10779245-id-420506.html
--------------------------------------------------------------------------------------------------------------------------------------------------------
-m: module_name
-p:protocol
-p tcp : 表示使用 TCP协议
-m tcp:表示使用TCP模块的扩展功能(tcp扩展模块提供了 --dport, --tcp-flags, --sync等功能)
只用 -p tcp 了话, iptables也会默认的使用 -m tcp 来调用 tcp模块提供的功能。但是 -p tcp 和 -m tcp是两个不同层面的东西,一个是说当前规则作用于 tcp 协议包,而后一是说明要使用iptables的tcp模块的功能 (--dport 等)
--------------------------------------------------------------------------------------------------------------------------------------------------------
-m conntrack --ctstate与-m state --state
ctstate是state的扩展版本(内核版本>=2.5开始支持),包括状态参数也是基本相同,不用过多纠结,不过既然出了新的写法,个人还是推荐新的写法和规则。由于UDP是无状态的传输协议,要注意使用。
对于Client是192.168.1.5:1031,Server是192.168.1.7:23。需求是Client可以主动连接Server,而反向主动的连接不可以。Client上防火墙规则如下:
TCP协议设置:
iptables -A INPUT -s 192.168.1.7 -p tcp --dport 1031 --sport 23 -m conntrack --ctstate ESTABLISHED -j ACCEPT
iptables -A OUTPUT -d 192.168.1.7 -p tcp --sport 1031 --dport 23 -m conntrack --ctstate NEW,ESTABLISHED -j ACCEPT
UDP协议设置:
iptables -A INPUT -s 192.168.1.7 -p udp --dport 1031 --sport 23 -m conntrack --ctstate ESTABLISHED -j ACCEPT
iptables -A OUTPUT -d 192.168.1.7 -p udp --sport 1031 --dport 23 -m conntrack --ctstate NEW,ESTABLISHED -j ACCEPT
ref:https://blog.csdn.net/dhRainer/article/details/84846417
--------------------------------------------------------------------------------------------------------------------------------------------------------
关于MARK的用法,策略路由
http://blog.chinaunix.net/uid-10167808-id-26001.html --Netfilter CONNMARK用法及分析(二)-- 内核代码分析
https://blog.csdn.net/suiyuan19840208/article/details/8952643 linux 下 nf_conntrack_tuple 跟踪记录
https://blog.csdn.net/lickylin/category_1587127.html
--------------------------------------------------------------------------------------------------------------------------------------------------------
负载均衡iptables实现
在Linux中使用iptables完成tcp的负载均衡有两种模式:随机、轮询
The statistic module support two different modes:
random:(随机) the rule is skipped based on a probability
nth:(轮询) the rule is skipped based on a round robin algorithm
说明iptables两种LB方式的具体实现:
系统中提供3个servers,下面我们通过配置iptables使流量均衡访问这3台server。
2.1 随机:(Random balancing)
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode random --probability 0.33 -j DNAT --to-destination 10.0.0.2:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode random --probability 0.5 -j DNAT --to-destination 10.0.0.3:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -j DNAT --to-destination 10.0.0.4:1234
rules说明:
第一条规则中,指定--probability 0.33 ,则说明该规则有33%的概率会命中,
第二条规则也有33%的概率命中,因为规则中指定 --probability 0.5。 则命中的概率为:50% * (1 - 33%)=0.33
第三条规则中,没有指定 --probability 参数,因此意味着当匹配走到第三条规则时,则一定命中,此时走到第三条规则的概率为:1 - 0.33 -0.33 ≈ 0.33。
由上可见,三条规则命中的几率一样的。此外,如果我们想修改三条规则的命中率,可以通过 --probability 参数调整。
假设有n个server,则可以设定n条rule将流量均分到n个server上,其中 --probability 参数的值可通过以下公式计算得到:
# 其中 i 代表规则的序号(第一条规则的序号为1)
# n 代表规则/server的总数
# p 代表第 i 条规则中 --probability 的参数值
p=1/(n−i+1)
注意:因为iptables中,规则是按顺序匹配的,由上至下依次匹配,因此设计iptables规则时,要严格对规则进行排序。因此上述三条规则的顺序也不可以调换,不然就无法实现LB均分了。
2.2 轮询 (Round Robin)
轮询算法中有两个参数:
n: 指每 n 个包
p:指第 p 个包
在规则中 n 和 p 代表着: 从第 p 个包开始,每 n 个包执行该规则。
这样可能有点绕口,直接看栗子吧:
还是上面的例子,有3个server,3个server轮询处理流量包,则规则配置如下:
# every:每n个包匹配一次规则
# packet:从第p个包开始
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode nth --every 3 --packet 0 -j DNAT --to-destination 10.0.0.2:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -m statistic --mode nth --every 2 --packet 0 -j DNAT --to-destination 10.0.0.3:1234
iptables -A PREROUTING -t nat -p tcp -d 192.168.1.1 --dport 27017 -j DNAT --to-destination 10.0.0.4:1234
REF:
https://scalingo.com/articles/2018/04/20/iptables.html
ref:https://blog.csdn.net/ksj367043706/article/details/89764546
--------------------------------------------------------------------------------------------------------------------------------------------------------
iptables和tc(Traffic Control,QDISC队列控制)来进行限速
https://blog.csdn.net/snrnjhna/article/details/49908339
https://my.oschina.net/adailinux/blog/1631371
-------------------------------------------------
开放7089 7085 34567 7000端口,发现不通
iptables -A INPUT -p tcp --dport 7089 -j ACCEPT
iptables -A INPUT -p tcp --dport 7085 -j ACCEPT
iptables -A INPUT -p tcp --dport 34567 -j ACCEPT
iptables -A INPUT -p tcp --dport 7000 -j ACCEPT
后改成如下通了
iptables -I INPUT -p tcp --dport 7089 -j ACCEPT
iptables -I INPUT -p tcp --dport 7085 -j ACCEPT
iptables -I INPUT -p tcp --dport 34567 -j ACCEPT
iptables -I INPUT -p tcp --dport 7000 -j ACCEPT
[root@metalabs fr]# iptables -vnL INPUT --line-numbers
Chain INPUT (policy ACCEPT 0 packets, 0 bytes)
num pkts bytes target prot opt in out source destination
1 771K 989M ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:7000
2 65848 2779K ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:34567
3 0 0 ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:7085
4 111K 4669K ACCEPT tcp -- * * 0.0.0.0/0 0.0.0.0/0 tcp dpt:7089
5 471K 473M ACCEPT all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate RELATED,ESTABLISHED
6 0 0 ACCEPT all -- lo * 0.0.0.0/0 0.0.0.0/0
7 11799 616K INPUT_direct all -- * * 0.0.0.0/0 0.0.0.0/0
8 11799 616K INPUT_ZONES_SOURCE all -- * * 0.0.0.0/0 0.0.0.0/0
9 11799 616K INPUT_ZONES all -- * * 0.0.0.0/0 0.0.0.0/0
10 222 8928 DROP all -- * * 0.0.0.0/0 0.0.0.0/0 ctstate INVALID
11 11456 600K REJECT all -- * * 0.0.0.0/0 0.0.0.0/0 reject-with icmp-host-prohibited
ipset介绍
ipset是iptables的扩展,它允许你创建 匹配整个地址集合的规则。而不像普通的iptables链只能单IP匹配, ip集合存储在带索引的数据结构中,这种结构即时集合比较大也可以进行高效的查找,除了一些常用的情况,比如阻止一些危险主机访问本机,从而减少系统资源占用或网络拥塞,IPsets也具备一些新防火墙设计方法,并简化了配置.官网:http://ipset.netfilter.org/
1.ipset安装
yum安装: yum install ipset
2.创建一个ipset
ipset create xxx hash:net (也可以是hash:ip ,这指的是单个ip,xxx是ipset名称)
ipset默认可以存储65536个元素,使用maxelem指定数量
ipset create blacklist hash:net maxelem 1000000 #黑名单
ipset create whitelist hash:net maxelem 1000000 #白名单
查看已创建的ipset
ipset list
3.加入一个名单ip
ipset add blacklist 10.60.10.xx
4.去除名单ip
ipset del blacklist 10.60.10.xx
5.创建防火墙规则,与此同时,allset这个IP集里的ip都无法访问80端口(如:CC攻击可用)
iptables -I INPUT -m set --match-set blacklist src -p tcp -j DROP
iptables -I INPUT -m set --match-set whitelist src -p tcp -j DROP
service iptables save
iptables -I INPUT -m set --match-set setname src -p tcp --destination-port 80 -j DROP
6.将ipset规则保存到文件
ipset save blacklist -f blacklist.txt
ipset save whitelist -f whitelist.txt
7.删除ipset
ipset destroy blacklist
ipset destroy whitelist
ipset destroy xxx
8.导入ipset规则
ipset restore -f blacklist.txt
ipset restore -f whitelist.txt
ipset的一个优势是集合可以动态的修改,即使ipset的iptables规则目前已经启动,新加的入ipset的ip也生效
转自:http://www.cnblogs.com/harlanzhang/p/6190674.html
iptables
iptables [-t 表名] 命令选项 [链名] [条件匹配] [-j 目标动作或跳转]
-t 表名 可以省略,指定规则存放在哪个表中,默认为filter表 用于存放相同功能的规则
filter表: 负责过滤功能能,
nat表: 网络地址转换功能
mangle表: 拆解报文 做出修改并重新封装的功能
raw表: 关闭nat表上启用的连接追踪机制
命令选项
-A 在指定链的末尾添加(append)一条新的规则
-D 删除(delete)指定链中的某一条规则,可以按规则序号和内容删除
-I 在指定链中插入(insert)一条新的规则,默认在第一行添加
-R 修改、替换(replace)指定链中的某一条规则,可以按规则序号和内容替换
-L 列出(list)指定链中所有的规则进行查看
-E 重命名用户定义的链,不改变链本身
-F 清空(flush)
-N 新建(new-chain)一条用户自己定义的规则链
-X 删除指定表中用户自定义的规则链(delete-chain)
-P 设置指定链的默认策略(policy)
-Z 将所有表的所有链的字节和数据包计数器清零
-n 使用数字形式(numeric)显示输出结果
-v 查看规则表详细信息(verbose)的信息
-V 查看版本(version)
-h 获取帮助(help)
链名 链是指很多规则串在一起组成一条链条,有先后顺序,总共就几个,根据规则分类的
INPUT 针对网络进入的报文规则
OUTPUT 针对网络出的报文规则
PREROUTING 路由前
POSTROUTING 路由后
FORWARD 转发
也可以自定义链,但是自建链最终还是要放到上面的链上
条件匹配 选择匹配的选项
-p TCP/UDP/ICMP/all : 匹配的连接类型
-s ip/网段/hostname等 : 匹配source的具体项
-d ip/网段/hostname等 : 匹配destination的具体项
-i eth0等interface name
-m match extended match
–sport source port
–dport destination port
-j target 指定匹配上规则后的具体动作
ACCEPT 允许数据包通过
DROP 直接丢弃数据包,不给任何回应信息
REJECT 拒绝数据包通过,必要时会给数据发送端一个响应的信息。
LOG在/var/log/messages文件中记录日志信息,然后将数据包传递给下一条规则
当自定义链时 在挂载自定义链到具体链时在这里指定自定义链
日常使用
iptables -L -nv 查看规则 iptables -L 链名字 查看某个链的规则 -line-numbers 列数规则的编号,这个编号可用于删除
iptables -I INPUT -s 11.250.199.16 -j DROP 在INPUT链首上插入一条规则,丢弃 11.250.199.16的访问
iptables -A INPUT -s 192.168.0.0/24 -j ACCEPT 在INPUT链尾上插入一条规则,允许 192.168 网段的访问 -A换为 -D就是删除
iptables -A FORWARD -s 192.168.1.11 -j REJECT 拒绝转发来自192.168.1.10主机的数据
iptables -I INPUT -s 121.14.48.1 -m statistic --mode random --probability 0.5 -j DROP 50%丢包
iptables -A INPUT -p tcp -s 11.160.13.129 --dport 3306 -j DROP 丢弃通过tcp连接 3306端口的访问
iptables -D INPUT 1 删除INPUT链的第一条规则
iptables -F INPUT 清空此链中的规则
service iptables save 它能把规则自动保存在/etc/sysconfig/iptables中, 当计算机启动时,rc.d下的脚本将用命令iptables-restore调用这个文件,从而就自动恢复了规则 需要yum install iptables-services
创建自定义链
iptables -N xxx 创建自定义链xxx
iptables -I xxx -s 11.250.199.16 -j DROP 对自定义链设置规则
注意: 到此为止这个自定义链都是无用的,因为没有在任何的默认链中引用
iptables -I INPUT -ptcp --dport 3306 -j xxx 将自定义链xxx挂到INPUT链上 这时候次链就生效了
iptables -E xxx new_xxx 修改自定义链名字 修改了名字引用自动生效
iptables -X new_xxx 删除自定义链,但是要满足两个条件
1.自定义链没有被任何默认链引用 有的话通过 iptables -D INPUT 1 删除
2.自定义链中没有任何规则 有的话 iptables -F new_xxx 清空
ipset
ipset是iptables的扩展,它允许你创建 匹配整个地址集合的规则。而不像普通的iptables链只能单IP匹配, ip集合存储在带索引的数据结构中,这种结构即时集合比较大也可以进行高效的查找,除了一些常用的情况,比如阻止一些危险主机访问本机,从而减少系统资源占用或网络拥塞,IPsets也具备一些新防火墙设计方法,并简化了配置.官网:http://ipset.netfilter.org/
ipset create blacklist hash:net maxelem 1000000
创建名为blacklist的ipset
hash:net 用什么进行hash ,也可以是hash:ip 就只能ip不能网段 hash:ip,port ip+port进行hash
ipset默认可以存储65536个元素,使用maxelem指定数量
也可以有timeout 数字 这种参数,指定这个集合里默认的超时时间单位s,超时后会自动把里面的对象删除
ipset list 查看已创建的ipset ipset list xxx 也可以带名字
ipset add blacklist 10.60.10.10 加入一个名单ip 也可以是网段
ipset add blacklist 6.6.6.6 timeout 60 指定这个ip的超时时间,超时会自动被删除了 前提是create要有timeout 0 (0表示里面的对象可有超时可没有)
ipset -exist add blacklist 6.6.6.6 timeout 100 重新为其指定超时时间
ipset del blacklist 10.60.10.xx 去除名单ip
ipset flush 清空所有集合 ipset flush blacklist 清空blacklist集合
ipset destroy blacklist 删除ipset 不能有任何下游依赖 ipset destroy 销毁所有集合
如果这个集合被链使用着不能删除 需要先去掉 iptables -D INPUT 1
如果这个集合非空不能删除 需要ipset flush blacklist
如果这个集合有被其他链使用着也不能被删除 需要 iptables -F 链名 清空链下的内容
ipset save blacklist -f blacklist.txt 将ipset规则保存到文件
ipset save blacklist 输出到标准输出 ipset save 输出所有集合到标准输出
ipset restore -f blacklist.txt 导入ipset规则 这个规则其实就是一些语句,必须ipsetname不存在才能导入
ipset restore 根据输入内容导入
ipset rename old_name new_name 改名
iptables -I INPUT -m set --match-set blacklist src -p tcp --dport 80 -j DROP 使用ipset集合到INPUT链,相当于就是批量添加
service ipset save save后重启自动生效 需要yum install ipset-service 会把配置放到/etc/sysconfig/ipset.d/ 下
ipset 不支持0.0.0.0/0 所有ip,可以替换为 0.0.0.0/1 128.0.0.0/1
ipset+自定义链
ipset create WhiteList hash:net maxelem 1000000 # 创建白名单集合
iptables -N xxxx # 创建自定义链xxxx
iptables -I xxxx -mset --match-set WhiteList src -j ACCEPT # 匹配白名单的包予以通过 -I换为-D就是删除这个规则
iptables -A xxxx -j REJECT #拦截所有未通过白名单的包 不加任何区域默认为 0.0.0.0/0 all
iptables -I INPUT -ptcp --dport 3306 -j xxxx #将链挂到input中
总结使用规则
规则的顺序
已经被前面规则匹配的,iptables会对报文执行相应的-j动作,后面的规则就不能再匹配了,已经执行动作了。只有没有匹配的才会继续匹配下面的规则
所以针对相同服务的规则,更严格的规则应该放在前面,这样在前面就能挡掉大部分的连接,减少过多的匹配耗时
当规则中存在多个匹配条件时,条件之间是与的关系, 比如既有-s 又有 -dport 又有-p 这些是与的关系
要将更容易匹配到的规则放在最前面 跟第一条有所矛盾
比如数据库服务的白名单,最多访问数据库的是应用,所以应用白名单规则应该放在最前面避免影响多数连接的匹配耗时
当使用iptables做网络防火墙时,要考虑方向性,即进入的和出去的网络
在做白名单服务时,应当把链的默认策略设置为ACCEPT,链的最后端设置为REJECT规则实现白名单机制
假如把默认设置为DROP,后端设置为ACCEPT时候,当后端规则被清空了,则管理员请求也会被drop
参考
http://www.zsythink.net/archives/tag/iptables/ 14节详细讲解
https://www.cnblogs.com/metoy/p/4320813.html 快速查看指令
https://www.cnblogs.com/vijayfly/p/7205559.html ipset使用
https://www.cnblogs.com/CasonChan/p/5319364.html ipset详细使用

