tesla V100 显卡和2080ti显卡相比,为啥工业部署上 大家用V100呢?

术业有专攻。对于消费级用户来说,GPU就是玩游戏,对于专业人员来说,GPU是计算工具,俗话说,一分钱一分货。
首先简单说明下专业计算卡和消费级游戏显卡的区别。
对于消费级用户来说GPU的浮点计算能力可以忽略不计,因为日常应用根本涉及不到,所以追求性价比的消费级用户,不会为没用的高双精度浮点运算能力买单。而对于专业领域来说,准确性是计算结果的重要指标,双精度浮点运算能力直接影响计算的准确性和时效性。
GeForce产品对于计算精度要求比较低,也许对于普通用户来说,即使发现一些数据下次也会忽略不计,比如显存错误,而专业计算卡比如Tesla V100对数据准确性和及时错误数据修正能力都非常依赖。其他方面还有诸如针对专业软件的针对性的GPU加速优化、显存的配备方面都有明显的不同。
说到NVIDIA Tesla V100,它采用的是NVIDIA Volta™架构,是科学计算和人工智能时代的理想计算引擎。从语音识别到训练虚拟个人助理和教会自动驾驶汽车自动驾驶,数据科学家们正利用人工智能解决日益复杂的挑战。解决此类问题需要花大量时间密集训练复杂性飞速增长的深度学习模型。V100 拥有 640 个 Tensor Core,是世界上第一个突破 100 万亿次 (TFLOPS) 深度学习性能障碍的 GPU。新一代 NVIDIA NVLink 以高达 300 GB/s 的速度连接多个 V100 GPU,在全球打造出功能极其强大的计算服务器。现在,在之前的系统中需要消耗数周计算资源的人工智能模型在几天内就可以完成训练。随着训练时间的大幅缩短,人工智能现在可以解决各类新型问题。


而在推理方面,V100 GPU 可提供比 CPU 服务器高 30 倍的推理性能。


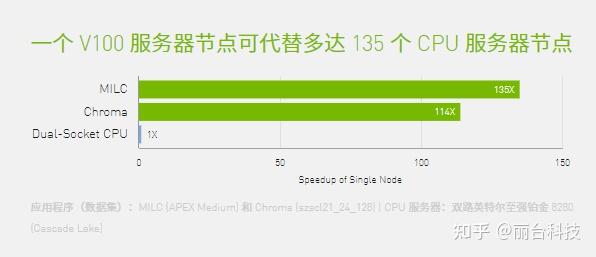
同时,V100 的设计能够融合人工智能和高性能计算。它为高性能计算系统提供了一个平台,在用于科学模拟的计算机科学和用于在数据中发现见解的数据科学方面表现优异。通过在一个统一架构内搭配使用 NVIDIA CUDA® Core和Tensor Core配备 V100 GPU 的单台服务器可以取代数百台仅配备通用 CPU 的服务器来处理传统的高性能计算和人工智能工作负载。现在,每位研究人员和工程师都可以负担得起使用人工智能超级计算机处理最具挑战性工作的做法。